This is the second of a Protein Embedding with ProteinBERT and STRING. On this part, we are gonna build a graph neural network (GNN) to update the embeddings of PorteinBERT with the information about the STRING network.
We will keep using the Unfolded protein binding (GO:0051082) ontology which belongs to the heat shock response. As before, the reason is because this was a gene set that appears significant on my thesis (Functional analysis of transcriptomes of Coffea arabica L. related to thermal stress) and because I don’t have much power on my laptop.
Creating and Loading the Unfolded Protein Binding Dataset
Before creating the neural network, we need data. So, for this I downloaded 60 plant species as zip files from STRING database. The reason I chooosed only plants, is because the heat shock proteins on plants are compartmentalized. This means, that there are specific heat shock proteins for the chloroplat, nucleus, mitocondria, plastids and cytoplasm. Using only plants in this case will result in a better training for this small part of the metabolism.
Other important thing to mention is that due to the size of the plants networks and the capacities of my laptop, I’m only using the Unfolded protein binding for these 60 species. If you have enough computing resources, you can try using the complete network from all these 60 species to train a robust model.
Great! Once downloaded the data, we need to create a dataset that pytorch geometric can use. For this, we need to use the Dataset object from pytorch geometric.
See the code below:
Code
class UnfoldedProteinBinding(Dataset):def__init__(self, root, transform=None, pre_transform=None, pre_filter=None):self.batch_size =2# adapt it according to your ram and gpu memmorysuper(UnfoldedProteinBinding, self).__init__(root, transform, pre_transform, pre_filter)@propertydef raw_file_names(self):returnself._get_zip_files()def _get_zip_files(self): files = os.listdir(self.raw_dir) zip_files = [f for f in files if f.endswith(".zip")]return zip_files@propertydef processed_file_names(self): num_zip_files =len(self.raw_file_names)return [f"data_{i}.pt"for i inrange(num_zip_files)]def download(self):# Download to `self.raw_dir`.passdef process(self):# gpu device only on linux system gpus = tf.config.experimental.list_physical_devices('GPU')iflen(gpus) >0:try:for gpu in gpus: tf.config.experimental.set_memory_growth(gpu, True)exceptRuntimeErroras e:print(e)else:print(f"Not gpus available")if os.name =="nt":print("Not gpus detected because you are using Windows system, Device: CPU")# check that we already processed the filesiflen(os.listdir(self.processed_dir)) ==len(self.raw_file_names)+2:passelse:for species inself.raw_paths:print(species)# reading interactions from tsv filewith zipfile.ZipFile(species, 'r') as z: file_names = z.namelist() tsv_files = [fileforfilein file_names iffile.endswith('interactions.tsv')]for tsv_file in tsv_files:with z.open(tsv_file) as f: df = pd.read_csv(f, sep='\t')# reading fasta filewith zipfile.ZipFile(species, 'r') as z: file_names = z.namelist() tsv_files = [fileforfilein file_names iffile.endswith('protein_sequences.fa')]for tsv_file in tsv_files:with z.open(tsv_file) as f: f_text = io.TextIOWrapper(f) protein_sequences_dict =self._read_proteins_from_fasta(f_text)# get unique proteins unique_proteins =set(df['node1_string_id']).union(set(df['node2_string_id']))# filter unique proteins on a dict filtered_protein_dict = {protein: seq for protein, seq in protein_sequences_dict.items() if protein in unique_proteins}# getting the larger sequence for the proteinbert embedding sequences =list(filtered_protein_dict.values())# protein_names = list(filtered_protein_dict.keys()) longest_sequence_length =max(len(seq) for seq in sequences)# use protein bert to get embeddings batch_size =self.batch_size # Adjust based on your GPU memory seq_len = longest_sequence_length+2 global_embeds = [] local_embeds = []for i inrange(0, len(sequences), batch_size): batch_seqs = sequences[i:i + batch_size] local_representation, global_representation =self._get_embeddings(batch_seqs, seq_len=seq_len, batch_size=batch_size) global_embeds.extend(global_representation) local_embeds.extend(local_representation) global_embeds = np.array(global_embeds) local_embeds = np.array(local_embeds)# encode the protein names lbl_protein = preprocessing.LabelEncoder() df.node1_string_id = lbl_protein.fit_transform(df.node1_string_id.values) df.node2_string_id = lbl_protein.fit_transform(df.node2_string_id.values)# generate edge index edge_index =self._load_edge_csv(df=df, src_index_col="node1_string_id", dst_index_col="node2_string_id", link_index_col="combined_score") edge_index = torch.LongTensor(edge_index)# get class for the graph y =self._find_species_classes(self.root+"/raw/species.xlsx",species).values index = y.copy()[0] y = torch.Tensor(y).to(torch.long)# create pytorch geometric data data = Data(x=global_embeds,edge_index=edge_index, y=y)# save as .pt file according to the index (class) torch.save(data, osp.join(self.processed_dir,f"data_{index}.pt"))def _read_proteins_from_fasta(self, fasta_file): protein_dict = {}for record in SeqIO.parse(fasta_file, "fasta"): protein_dict[record.id] =str(record.seq)return protein_dictdef _get_embeddings(self, seq, seq_len=512, batch_size=1): pretrained_model_generator, input_encoder = load_pretrained_model() model = get_model_with_hidden_layers_as_outputs(pretrained_model_generator.create_model(seq_len=seq_len)) encoded_x = input_encoder.encode_X(seq, seq_len) local_representations, global_representations = model.predict(encoded_x, batch_size=batch_size)return local_representations, global_representationsdef _load_edge_csv(self, df, src_index_col, dst_index_col, link_index_col): edge_index=None src = [protein1 for protein1 in df[src_index_col]] dst = [protein2 for protein2 in df[dst_index_col]] edge_attr = torch.from_numpy(df[link_index_col].values).view(-1,1) edge_index = [[], []]for i inrange(edge_attr.shape[0]):if edge_attr[i]: edge_index[0].append(src[i]) edge_index[1].append(dst[i])return edge_indexdef _find_species_classes(self, file_path, species_path):# Load the Excel file into a pandas DataFrame df = pd.read_excel(file_path)# Ensure the columns 'species' and 'class' existif'species'notin df.columns or'class'notin df.columns:raiseValueError("The input file must contain 'species' and 'class' columns.")# Identify rows where "scientific name" is present in the "species" column (case insensitive) extract_pattern = [i.split("\\") for i in species_path.split("_")[0:2]] extract_pattern = [i[-1] for i in extract_pattern] extract_pattern =" ".join(extract_pattern)print(f"Extracted pattern: {extract_pattern}") mask = df['species'].str.contains(extract_pattern, case=False, na=False)# Return the corresponding "class" values result = df.loc[mask, 'class']return resultdeflen(self):returnlen(self.processed_file_names)def get(self, idx): data = torch.load(osp.join(self.processed_dir, f'data_{idx}.pt'))return data
Basically what this code does, is using the .tsv and .fasta files to create a Data object that stores 3 things:
The embedding of ProteinBERT as node features.
The edge_index which is the connections of the network.
A number representing the plant species.
We can verifiy that the data was created and loaded:
Code
dataset = UnfoldedProteinBinding(root="data/")
Code
dataset[0]
Data(x=[158, 15599], edge_index=[2, 8578], y=[1])
Spliting the Data
Once we have the data loaded, we need to split it to trainning and test datasets. For this, we can use random_split and load these two datasets to a DataLoader from pytorch geometric.
I set batch to one because I dont have much computer resources and because if I increase the number of batches, I need to add a for loop on the GNN class due to the different number of nodes for each species. You are free to modify this for a larger scale training.
Code
from torch_geometric.loader import DataLoadertrain_dataset, test_dataset = torch.utils.data.random_split(dataset, [50, 10])batch_size =1# Adjust based on your memory capacitytrain_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
Okay! We are ready to create our graph neural network. We are gonna use GraphSAGE for this task because it’s easy to implement and faster to train.
GNNStack
The GNNStack class, takes as input the ProteinBERT embeddings and the edge index and returns the updated node embeddings. Notice that we are using a built-in GraphSAGE (SAGEConv) from pytorch geometric.
Code
from torch_geometric.nn import SAGEConvclass GNNStack(torch.nn.Module):def__init__(self, input_dim, hidden_dim, output_dim, dropout, num_layers:int, emb=False):super(GNNStack, self).__init__()self.dropout = dropoutself.num_layers = num_layersself.emb = embself.convs = nn.ModuleList()for layer inrange(self.num_layers): in_channels = input_dim if layer ==0else hidden_dim out_channels = hidden_dim self.convs.append(SAGEConv(in_channels, out_channels, normalize=True))self.post_mp = nn.Sequential( nn.Linear(hidden_dim, hidden_dim), nn.Dropout(self.dropout), nn.Linear(hidden_dim, hidden_dim) ) def forward(self, x, edge_index):for i inrange(self.num_layers): x =self.convs[i](x, edge_index) x = F.gelu(x) x = F.dropout(x, p=self.dropout,training=self.training) x =self.post_mp(x)ifself.emb ==True:return xreturn F.log_softmax(x, dim=1)def loss(self, pred, label):return F.nll_loss(pred, label)
A function to save the model:
Code
def save_torch_model(model,epoch,PATH:str,optimizer):print(f"Saving Model in Path {PATH}") torch.save({'epoch': epoch,'model_state_dict': model.state_dict(),'optimizer':optimizer, }, PATH)
Once we have the updated protein embeddings, we need to create a prediction head that will calculate the probability that two proteins interact.
The LinkPredictorHead takes as input two vectors that corresponds to the edge indeces from a specific network and return a estimated probability that these nodes interact.
Notice that to the last layer, a multi layer perceptron is applied.
Code
class LinkPredictorHead(nn.Module):def__init__(self, in_channels:int, hidden_channels:int, out_channels:int, n_layers:int,dropout_probabilty:float=0.3):super(LinkPredictorHead, self).__init__()self.dropout_probabilty = dropout_probabilty # dropout probabilityself.mlp_layers = nn.ModuleList() # ModuleList: is a list of modulesself.non_linearity = F.relu # non-linearityfor i inrange(n_layers -1): if i ==0:self.mlp_layers.append(nn.Linear(in_channels, hidden_channels)) # input layer (in_channels, hidden_channels)else:self.mlp_layers.append(nn.Linear(hidden_channels, hidden_channels)) # hidden layers (hidden_channels, hidden_channels)self.mlp_layers.append(nn.Linear(hidden_channels, out_channels)) # output layer (hidden_channels, out_channels)def reset_parameters(self):for mlp_layer inself.mlp_layers: mlp_layer.reset_parameters()def forward(self, x_i, x_j): x = x_i * x_j # element-wise multiplicationfor mlp_layer inself.mlp_layers[:-1]: # iterate over all layers except the last one x = mlp_layer(x) # apply linear transformation x =self.non_linearity(x) # Apply non linear activation function x = F.dropout(x, p=self.dropout_probabilty,training=self.training) # Apply dropout x =self.mlp_layers[-1](x) # apply linear transformation to the last layer x = torch.sigmoid(x) # apply sigmoid activation function to get the probabilityreturn x
Now, let’s check if our GNNStack and LinkPredictorHead works on a single graph:
Code
for batch in train_loader:print(batch) x = torch.FloatTensor(batch.x[0]) emb = model(x, batch.edge_index) x = link_model_pred(emb[batch.edge_index[0]], emb[batch.edge_index[1]])print(x)break
Let’s define a training function that for each batch, will get the updated embedding using GrapgSAGE and get the estimated probaiblities using the link predictor head. Now, we need to sample negatives edges so the model can learn which edges are good an which aren’t. Finally, the negative log-likelihood is calculated with the positive and negative edges.
Code
def train(model, link_predictor, dataloader, optimizer, device:str):if model !=None: model.train() link_predictor.train() total_loss =0for batch in tqdm(dataloader): x, edge_index = batch.x[0], batch.edge_index x = torch.FloatTensor(x).to(device) edge_index = edge_index.to(device) optimizer.zero_grad() if model !=None: node_emb = model(x, edge_index) # Embed Bert Embeddigns with graphsage (N, d) else: node_emb = x # Else (None) use Bert Embedddings# Predict the class probabilities on the batch of positive edges using link_predictor#print(node_emb[edge_index[0]].shape) pos_pred = link_predictor(node_emb[edge_index[0]], node_emb[edge_index[1]]) # (B, )# Sample negative edges (same number as number of positive edges) and predict class probabilities # (2,N) = (2,P) = (2,|E|) neg_edge = negative_sampling(edge_index = edge_index, # Possitve PPI's num_nodes = x.shape[0], # Total number of nodes in graph num_neg_samples = edge_index.shape[1], # Same Number of edges as in positive example force_undirected =True) # Our graph is undirected neg_pred = link_predictor(node_emb[neg_edge[0]], node_emb[neg_edge[1]]) # (Ne,)# Compute the corresponding negative log likelihood loss on the positive and negative edges loss =-torch.log(pos_pred +1e-15).mean() - torch.log(1- neg_pred +1e-15).mean()# Backpropagate and update parameters loss.backward() optimizer.step() total_loss += loss.item()return total_loss /len(dataloader)
Testing Function
For the testing function, as Perez et al. mention:
“if we were to use all the PPI to embed the graph it would be practically cheating (since our embedding would have this information). Therefore (for the evaluation loop) we will randomly drop a percentage of PPIs by doing two steps: Randomly permuted the edge_index and Dropping a percentage of PPI for embedding and leaving another percentage for inference”
Then, we use the GNNStack and the LinkPredictorHead to get the estimated probability on the permuted edge_index. Also, we need to get negative edges and predict the probability of their interactions. The idea is to get high accuracy for the positive and negatives edges so we are sure that the model is performing better each epoch of training.
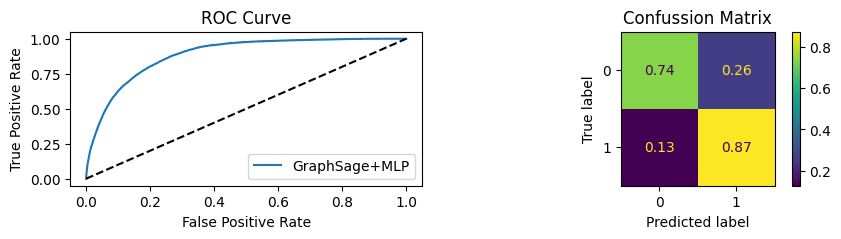
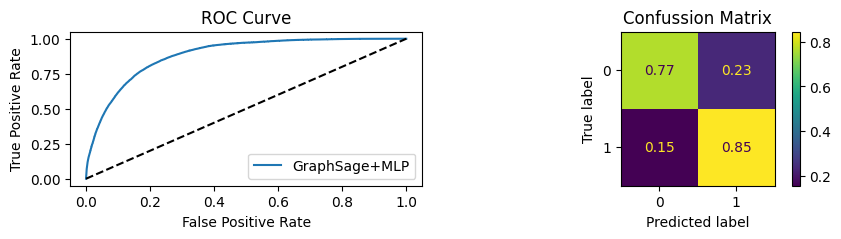
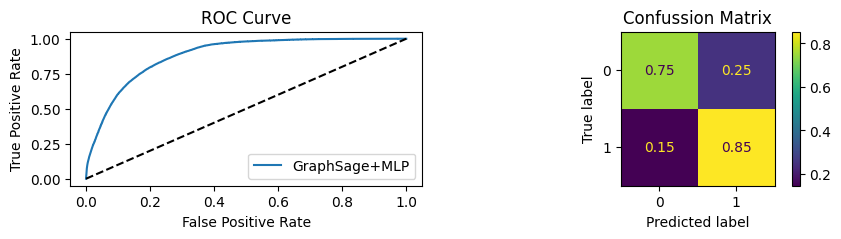
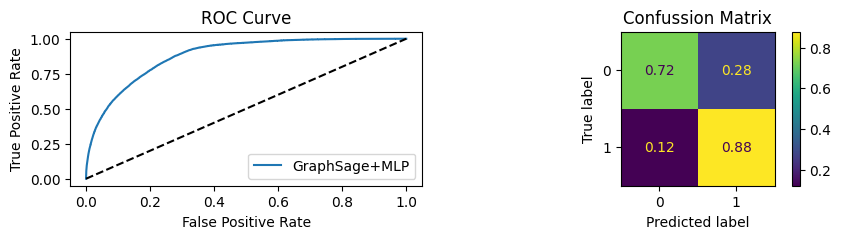
An extra chunk of code is inside the function that will show the AUC/ROC plot and Confusion matrix plot.
Code
def evaluate(model, predictor,dataloader,device:str,threshold=0.5,ppi_:int=0.9,verbose:bool=False,best_accuracy=0,show_extra_metrics:bool=False):if model !=None: model.eval() possitive_acc =0 negative_acc =0 batches =0if show_extra_metrics: yhat_total = [] y_total = []for batch in dataloader: # Get X and Index from Dataste x, edge_index = batch.x[0], batch.edge_index x = torch.FloatTensor(x).to(device) edge_index = edge_index.to(device) number_of_edges = edge_index.size(1) # Retrive number of edges permutations = torch.randperm(number_of_edges) # Create Permutations for edge index edge_index = edge_index[:,permutations] # Run permutation limit =int(ppi_*number_of_edges) # get limit (based on ppis to embed) ppi_index_embed = edge_index[:,0:limit] # PPI to embed with GraphSage ppi_index_infer = edge_index[:,limit:] # PPI to make inference# x = x.squeeze(dim=1)# x ,ppi_index_embed = x.to(device) , ppi_index_embed.to(device) if model !=None: node_emb = model(x,ppi_index_embed) # Get all node embeddingselse: node_emb = x.cpu() # Else (None) use Bert Embedddingsif verbose:print(f" {limit} Positive Protein Interactions were used to Embed a graph with {number_of_edges} ppi's")del ppi_index_embed with torch.no_grad():### Positive PPI ### positive_pairs_embeddings = node_emb[ppi_index_infer[0]], node_emb[ppi_index_infer[1]] predictions = predictor(positive_pairs_embeddings[0], positive_pairs_embeddings[1]) y = torch.ones_like(input=predictions) predictions,y = predictions.cpu(),y.cpu() possitive_acc += accuracy_score(predictions > threshold ,y)if show_extra_metrics: yhat_total.extend(predictions.tolist()) y_total.extend(y.tolist())else:del y, predictions , positive_pairs_embeddings,ppi_index_infer### Negative PPI ## neg_edge = negative_sampling(edge_index = edge_index, # Possitve PPI's num_nodes = x.shape[0], # Total number of nodes in graph num_neg_samples = edge_index.shape[1], # Same Number of edges as in positive example force_undirected =True) # Our graph is undirected negative_pairs_embeddings = node_emb[neg_edge[0]], node_emb[neg_edge[1]] predictions = predictor(negative_pairs_embeddings[0], negative_pairs_embeddings[1]) y = torch.zeros_like(input=predictions) predictions,y = predictions.cpu(),y.cpu() negative_acc += accuracy_score(predictions > threshold,y)if show_extra_metrics: yhat_total.extend(predictions.tolist()) y_total.extend(y.tolist())else:del y, predictions ,negative_pairs_embeddings batches +=1 negative_acc = negative_acc/batches possitive_acc = possitive_acc/batches total_acc =0.5*possitive_acc +0.5*negative_accif show_extra_metrics ==False:print(f"Sensitivity (poss_acc):{possitive_acc:.4f} Specificity (negative_acc):{negative_acc:.4f} accuracy:{total_acc:.4f}")elif show_extra_metrics ==True: fig, ax = plt.subplots(1, 2,figsize=(10,2)) fpr, tpr, thresholds = metrics.roc_curve( y_total, yhat_total) sens = tpr spec =1- fpr j = sens + spec -1 opt_index = np.where(j == np.max(j))[0][0] op_point = thresholds[opt_index]print(f"Youdens index: {op_point:.4f} Sensitivity: {round(sens[opt_index],4)} Specificity: {round(spec[opt_index],4)}") ax[0].set_title("ROC Curve") ax[1].set_title("Confussion Matrix")if model ==None: ax[0].plot(fpr,tpr,label="MLP") else: ax[0].plot(fpr,tpr,label="GraphSage+MLP") ax[0].plot([0, 1], [0, 1], 'k--') ax[0].set_ylabel('True Positive Rate') ax[0].set_xlabel('False Positive Rate') ax[0].legend() cfm = metrics.confusion_matrix(y_total, np.array(yhat_total)> op_point) cmn = cfm.astype('float') / cfm.sum(axis=1)[:, np.newaxis] # Normalise disp = ConfusionMatrixDisplay(cmn) disp.plot(ax=ax[1]) plt.show()return total_acc
Training the Model
It’s time to train the model. First, let’s define some parameters:
model = GNNStack(input_dim, hidden_dim, hidden_dim, dropout,num_layers, emb=True).to(device) # the graph neural network that takes all the node embeddings as inputs to message pass and agregatelink_predictor = LinkPredictorHead(hidden_dim, hidden_dim, 1, num_layers , dropout).to(device) # the MLP that takes embeddings of a pair of nodes and predicts the existence of an edge between themoptimizer = torch.optim.Adam(list(model.parameters()) +list(link_predictor.parameters() ), lr=learning_rate)print(model)print(link_predictor)print(f"Models Loaded to {device}")
Replacing models:
with: Best models at GraphSage_epoch_1.pt link_predictor_epoch_1.pt
Saving Model in Path GraphSage_epoch_1.pt
Saving Model in Path link_predictor_epoch_1.pt
Epoch 2: loss: 1.38614
Sensitivity (poss_acc):0.8252 Specificity (negative_acc):0.2117 accuracy:0.5184
Replacing models: GraphSage_epoch_1.pt link_predictor_epoch_1.pt
with: Best models at GraphSage_epoch_2.pt link_predictor_epoch_2.pt
Saving Model in Path GraphSage_epoch_2.pt
Saving Model in Path link_predictor_epoch_2.pt
Epoch 3: loss: 1.38463
Sensitivity (poss_acc):0.9350 Specificity (negative_acc):0.2309 accuracy:0.5829
Replacing models: GraphSage_epoch_2.pt link_predictor_epoch_2.pt
with: Best models at GraphSage_epoch_3.pt link_predictor_epoch_3.pt
Saving Model in Path GraphSage_epoch_3.pt
Saving Model in Path link_predictor_epoch_3.pt
Epoch 4: loss: 1.3332
Sensitivity (poss_acc):0.8810 Specificity (negative_acc):0.3632 accuracy:0.6221
Replacing models: GraphSage_epoch_3.pt link_predictor_epoch_3.pt
with: Best models at GraphSage_epoch_4.pt link_predictor_epoch_4.pt
Saving Model in Path GraphSage_epoch_4.pt
Saving Model in Path link_predictor_epoch_4.pt
Epoch 5: loss: 1.23284
Sensitivity (poss_acc):0.9000 Specificity (negative_acc):0.3776 accuracy:0.6388
Replacing models: GraphSage_epoch_4.pt link_predictor_epoch_4.pt
with: Best models at GraphSage_epoch_5.pt link_predictor_epoch_5.pt
Saving Model in Path GraphSage_epoch_5.pt
Saving Model in Path link_predictor_epoch_5.pt
Epoch 9: loss: 1.12853
Sensitivity (poss_acc):0.9092 Specificity (negative_acc):0.4707 accuracy:0.6900
Replacing models: GraphSage_epoch_5.pt link_predictor_epoch_5.pt
with: Best models at GraphSage_epoch_9.pt link_predictor_epoch_9.pt
Saving Model in Path GraphSage_epoch_9.pt
Saving Model in Path link_predictor_epoch_9.pt
Epoch 12: loss: 1.06029
Sensitivity (poss_acc):0.7078 Specificity (negative_acc):0.6942 accuracy:0.7010
Replacing models: GraphSage_epoch_9.pt link_predictor_epoch_9.pt
with: Best models at GraphSage_epoch_12.pt link_predictor_epoch_12.pt
Saving Model in Path GraphSage_epoch_12.pt
Saving Model in Path link_predictor_epoch_12.pt
Epoch 14: loss: 1.04963
Sensitivity (poss_acc):0.8731 Specificity (negative_acc):0.5512 accuracy:0.7122
Replacing models: GraphSage_epoch_12.pt link_predictor_epoch_12.pt
with: Best models at GraphSage_epoch_14.pt link_predictor_epoch_14.pt
Saving Model in Path GraphSage_epoch_14.pt
Saving Model in Path link_predictor_epoch_14.pt
Epoch 17: loss: 0.98034
Sensitivity (poss_acc):0.8704 Specificity (negative_acc):0.5577 accuracy:0.7140
Replacing models: GraphSage_epoch_14.pt link_predictor_epoch_14.pt
with: Best models at GraphSage_epoch_17.pt link_predictor_epoch_17.pt
Saving Model in Path GraphSage_epoch_17.pt
Saving Model in Path link_predictor_epoch_17.pt
Epoch 19: loss: 0.97591
Sensitivity (poss_acc):0.7789 Specificity (negative_acc):0.6861 accuracy:0.7325
Replacing models: GraphSage_epoch_17.pt link_predictor_epoch_17.pt
with: Best models at GraphSage_epoch_19.pt link_predictor_epoch_19.pt
Saving Model in Path GraphSage_epoch_19.pt
Saving Model in Path link_predictor_epoch_19.pt
Epoch 28: loss: 0.86054
Sensitivity (poss_acc):0.8014 Specificity (negative_acc):0.6656 accuracy:0.7335
Replacing models: GraphSage_epoch_19.pt link_predictor_epoch_19.pt
with: Best models at GraphSage_epoch_28.pt link_predictor_epoch_28.pt
Saving Model in Path GraphSage_epoch_28.pt
Saving Model in Path link_predictor_epoch_28.pt
Epoch 29: loss: 0.8593
Sensitivity (poss_acc):0.8800 Specificity (negative_acc):0.6003 accuracy:0.7401
Replacing models: GraphSage_epoch_28.pt link_predictor_epoch_28.pt
with: Best models at GraphSage_epoch_29.pt link_predictor_epoch_29.pt
Saving Model in Path GraphSage_epoch_29.pt
Saving Model in Path link_predictor_epoch_29.pt
Epoch 35: loss: 0.80066
Sensitivity (poss_acc):0.8574 Specificity (negative_acc):0.6354 accuracy:0.7464
Replacing models: GraphSage_epoch_29.pt link_predictor_epoch_29.pt
with: Best models at GraphSage_epoch_35.pt link_predictor_epoch_35.pt
Saving Model in Path GraphSage_epoch_35.pt
Saving Model in Path link_predictor_epoch_35.pt
Epoch 36: loss: 0.82452
Sensitivity (poss_acc):0.8161 Specificity (negative_acc):0.6823 accuracy:0.7492
Replacing models: GraphSage_epoch_35.pt link_predictor_epoch_35.pt
with: Best models at GraphSage_epoch_36.pt link_predictor_epoch_36.pt
Saving Model in Path GraphSage_epoch_36.pt
Saving Model in Path link_predictor_epoch_36.pt
Epoch 37: loss: 0.795
Sensitivity (poss_acc):0.8560 Specificity (negative_acc):0.6546 accuracy:0.7553
Replacing models: GraphSage_epoch_36.pt link_predictor_epoch_36.pt
with: Best models at GraphSage_epoch_37.pt link_predictor_epoch_37.pt
Saving Model in Path GraphSage_epoch_37.pt
Saving Model in Path link_predictor_epoch_37.pt
Epoch 42: loss: 0.76536
Sensitivity (poss_acc):0.8773 Specificity (negative_acc):0.6335 accuracy:0.7554
Replacing models: GraphSage_epoch_37.pt link_predictor_epoch_37.pt
with: Best models at GraphSage_epoch_42.pt link_predictor_epoch_42.pt
Saving Model in Path GraphSage_epoch_42.pt
Saving Model in Path link_predictor_epoch_42.pt
Epoch 45: loss: 0.75666
Sensitivity (poss_acc):0.8784 Specificity (negative_acc):0.6495 accuracy:0.7639
Replacing models: GraphSage_epoch_42.pt link_predictor_epoch_42.pt
with: Best models at GraphSage_epoch_45.pt link_predictor_epoch_45.pt
Saving Model in Path GraphSage_epoch_45.pt
Saving Model in Path link_predictor_epoch_45.pt
Epoch 52: loss: 0.71855
Sensitivity (poss_acc):0.8371 Specificity (negative_acc):0.6921 accuracy:0.7646
Replacing models: GraphSage_epoch_45.pt link_predictor_epoch_45.pt
with: Best models at GraphSage_epoch_52.pt link_predictor_epoch_52.pt
Saving Model in Path GraphSage_epoch_52.pt
Saving Model in Path link_predictor_epoch_52.pt
Epoch 61: loss: 0.66578
Sensitivity (poss_acc):0.8348 Specificity (negative_acc):0.7032 accuracy:0.7690
Replacing models: GraphSage_epoch_52.pt link_predictor_epoch_52.pt
with: Best models at GraphSage_epoch_61.pt link_predictor_epoch_61.pt
Saving Model in Path GraphSage_epoch_61.pt
Saving Model in Path link_predictor_epoch_61.pt
Epoch 67: loss: 0.65321
Sensitivity (poss_acc):0.8725 Specificity (negative_acc):0.6989 accuracy:0.7857
Replacing models: GraphSage_epoch_61.pt link_predictor_epoch_61.pt
with: Best models at GraphSage_epoch_67.pt link_predictor_epoch_67.pt
Saving Model in Path GraphSage_epoch_67.pt
Saving Model in Path link_predictor_epoch_67.pt
Replacing models: GraphSage_epoch_67.pt link_predictor_epoch_67.pt
with: Best models at GraphSage_epoch_80.pt link_predictor_epoch_80.pt
Saving Model in Path GraphSage_epoch_80.pt
Saving Model in Path link_predictor_epoch_80.pt
Epoch 113: loss: 0.50896
Sensitivity (poss_acc):0.8924 Specificity (negative_acc):0.6953 accuracy:0.7939
Replacing models: GraphSage_epoch_80.pt link_predictor_epoch_80.pt
with: Best models at GraphSage_epoch_113.pt link_predictor_epoch_113.pt
Saving Model in Path GraphSage_epoch_113.pt
Saving Model in Path link_predictor_epoch_113.pt
Epoch 117: loss: 0.52405
Sensitivity (poss_acc):0.9112 Specificity (negative_acc):0.6921 accuracy:0.8017
Replacing models: GraphSage_epoch_113.pt link_predictor_epoch_113.pt
with: Best models at GraphSage_epoch_117.pt link_predictor_epoch_117.pt
Saving Model in Path GraphSage_epoch_117.pt
Saving Model in Path link_predictor_epoch_117.pt
Epoch 127: loss: 0.51036
Sensitivity (poss_acc):0.8763 Specificity (negative_acc):0.7330 accuracy:0.8047
Replacing models: GraphSage_epoch_117.pt link_predictor_epoch_117.pt
with: Best models at GraphSage_epoch_127.pt link_predictor_epoch_127.pt
Saving Model in Path GraphSage_epoch_127.pt
Saving Model in Path link_predictor_epoch_127.pt
Epoch 168: loss: 0.47142
Sensitivity (poss_acc):0.9055 Specificity (negative_acc):0.7056 accuracy:0.8055
Replacing models: GraphSage_epoch_127.pt link_predictor_epoch_127.pt
with: Best models at GraphSage_epoch_168.pt link_predictor_epoch_168.pt
Saving Model in Path GraphSage_epoch_168.pt
Saving Model in Path link_predictor_epoch_168.pt
Epoch 171: loss: 0.61125
Sensitivity (poss_acc):0.9161 Specificity (negative_acc):0.6978 accuracy:0.8070
Replacing models: GraphSage_epoch_168.pt link_predictor_epoch_168.pt
with: Best models at GraphSage_epoch_171.pt link_predictor_epoch_171.pt
Saving Model in Path GraphSage_epoch_171.pt
Saving Model in Path link_predictor_epoch_171.pt
Epoch 183: loss: 0.42708
Sensitivity (poss_acc):0.8720 Specificity (negative_acc):0.7587 accuracy:0.8154
Replacing models: GraphSage_epoch_171.pt link_predictor_epoch_171.pt
with: Best models at GraphSage_epoch_183.pt link_predictor_epoch_183.pt
Saving Model in Path GraphSage_epoch_183.pt
Saving Model in Path link_predictor_epoch_183.pt
Epoch 204: loss: 0.43305
Sensitivity (poss_acc):0.8786 Specificity (negative_acc):0.7546 accuracy:0.8166
Replacing models: GraphSage_epoch_183.pt link_predictor_epoch_183.pt
with: Best models at GraphSage_epoch_204.pt link_predictor_epoch_204.pt
Saving Model in Path GraphSage_epoch_204.pt
Saving Model in Path link_predictor_epoch_204.pt
Epoch 206: loss: 0.40325
Sensitivity (poss_acc):0.8794 Specificity (negative_acc):0.7583 accuracy:0.8188
Replacing models: GraphSage_epoch_204.pt link_predictor_epoch_204.pt
with: Best models at GraphSage_epoch_206.pt link_predictor_epoch_206.pt
Saving Model in Path GraphSage_epoch_206.pt
Saving Model in Path link_predictor_epoch_206.pt
Epoch 291: loss: 0.28131
Sensitivity (poss_acc):0.9179 Specificity (negative_acc):0.7221 accuracy:0.8200
Replacing models: GraphSage_epoch_206.pt link_predictor_epoch_206.pt
with: Best models at GraphSage_epoch_291.pt link_predictor_epoch_291.pt
Saving Model in Path GraphSage_epoch_291.pt
Saving Model in Path link_predictor_epoch_291.pt
Epoch 301: loss: 0.29137
Sensitivity (poss_acc):0.9161 Specificity (negative_acc):0.7305 accuracy:0.8233
Replacing models: GraphSage_epoch_291.pt link_predictor_epoch_291.pt
with: Best models at GraphSage_epoch_301.pt link_predictor_epoch_301.pt
Saving Model in Path GraphSage_epoch_301.pt
Saving Model in Path link_predictor_epoch_301.pt
Epoch 311: loss: 0.2875
Sensitivity (poss_acc):0.9044 Specificity (negative_acc):0.7480 accuracy:0.8262
Replacing models: GraphSage_epoch_301.pt link_predictor_epoch_301.pt
with: Best models at GraphSage_epoch_311.pt link_predictor_epoch_311.pt
Saving Model in Path GraphSage_epoch_311.pt
Saving Model in Path link_predictor_epoch_311.pt
Epoch 345: loss: 0.35241
Sensitivity (poss_acc):0.9142 Specificity (negative_acc):0.7485 accuracy:0.8313
Replacing models: GraphSage_epoch_311.pt link_predictor_epoch_311.pt
with: Best models at GraphSage_epoch_345.pt link_predictor_epoch_345.pt
Saving Model in Path GraphSage_epoch_345.pt
Saving Model in Path link_predictor_epoch_345.pt
Epoch 361: loss: 0.25936
Sensitivity (poss_acc):0.9076 Specificity (negative_acc):0.7554 accuracy:0.8315
Replacing models: GraphSage_epoch_345.pt link_predictor_epoch_345.pt
with: Best models at GraphSage_epoch_361.pt link_predictor_epoch_361.pt
Saving Model in Path GraphSage_epoch_361.pt
Saving Model in Path link_predictor_epoch_361.pt
Replacing models: GraphSage_epoch_361.pt link_predictor_epoch_361.pt
with: Best models at GraphSage_epoch_400.pt link_predictor_epoch_400.pt
Saving Model in Path GraphSage_epoch_400.pt
Saving Model in Path link_predictor_epoch_400.pt
Epoch 404: loss: 0.21484
Sensitivity (poss_acc):0.8955 Specificity (negative_acc):0.7831 accuracy:0.8393
Replacing models: GraphSage_epoch_400.pt link_predictor_epoch_400.pt
with: Best models at GraphSage_epoch_404.pt link_predictor_epoch_404.pt
Saving Model in Path GraphSage_epoch_404.pt
Saving Model in Path link_predictor_epoch_404.pt
Once the training is complete, we can load our best model and use it to see the AUC/ROC and Confussion matrix plot. Also, we can use it with validation data (comming!) to see how well this is performing.
Code
model = GNNStack(input_dim, hidden_dim, hidden_dim, dropout,num_layers, emb=True).to(device)best_graphsage_model_path =f"GraphSage_epoch_{404}.pt"best_link_predictor_model_path =f"link_predictor_epoch_{404}.pt"print(f"Loading best models: {best_graphsage_model_path }{best_link_predictor_model_path}")checkpoint = torch.load(best_graphsage_model_path)model.load_state_dict(checkpoint['model_state_dict'])model.eval()checkpoint = torch.load(best_link_predictor_model_path)link_predictor.load_state_dict(checkpoint['model_state_dict'])del checkpoint
Loading best models: GraphSage_epoch_404.pt link_predictor_epoch_404.pt
Run this part, to see the loss and accuracy acroos the epochs:
Is important to see how the model behaves with different percentages of protein-protein interactions:
Code
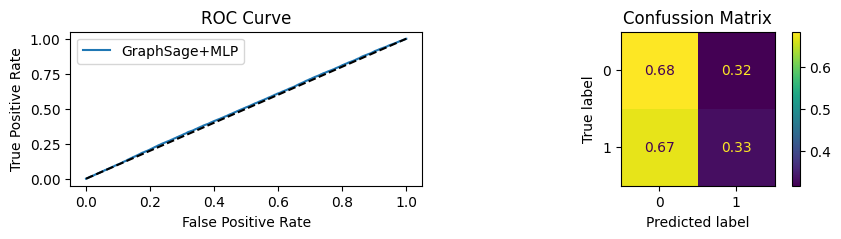
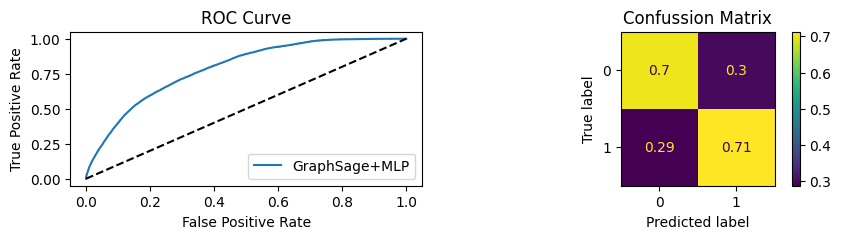
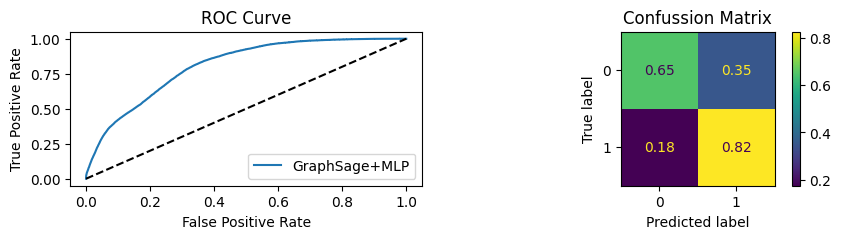
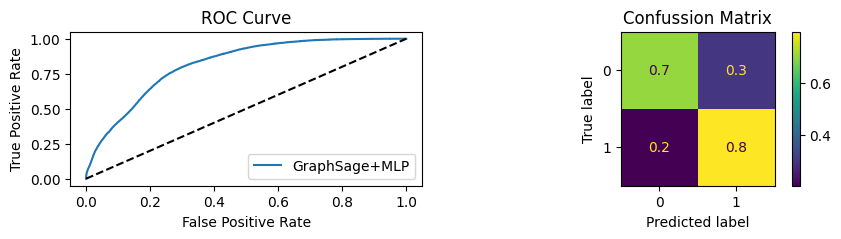
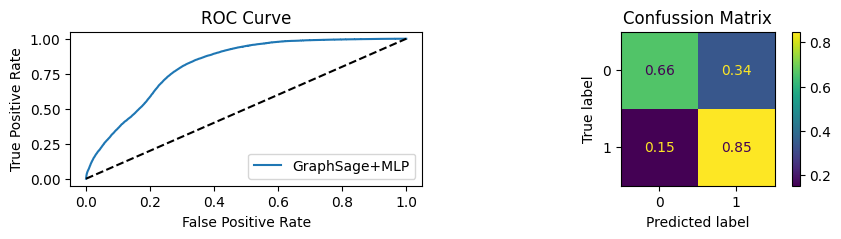
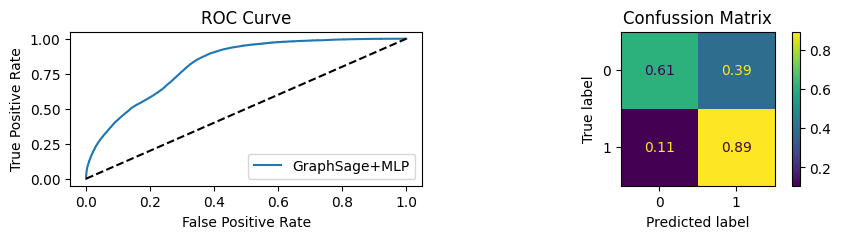
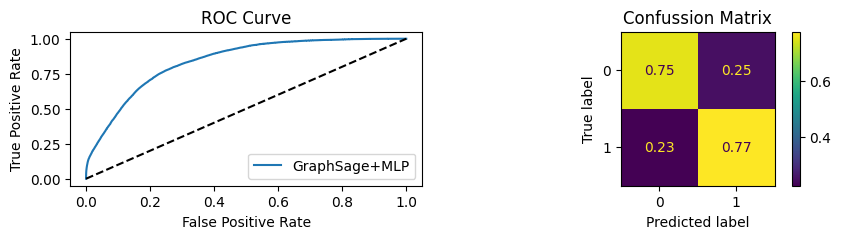
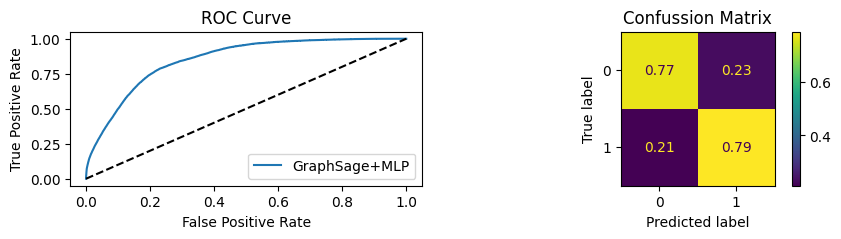
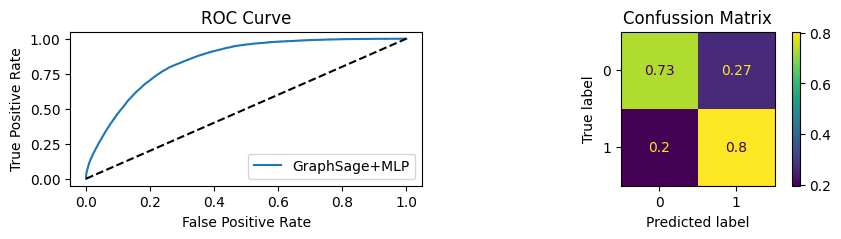
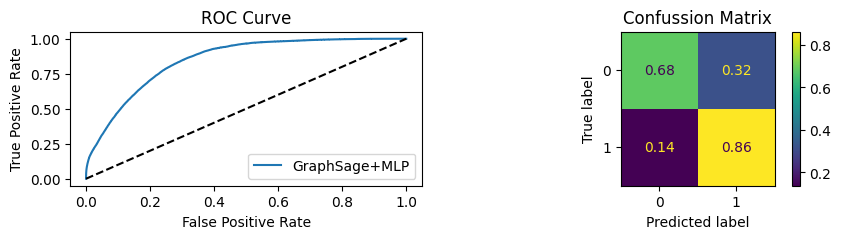
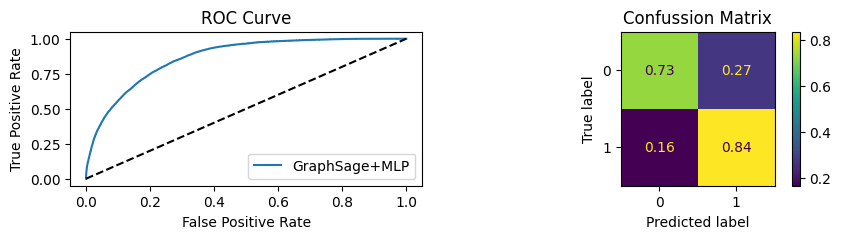
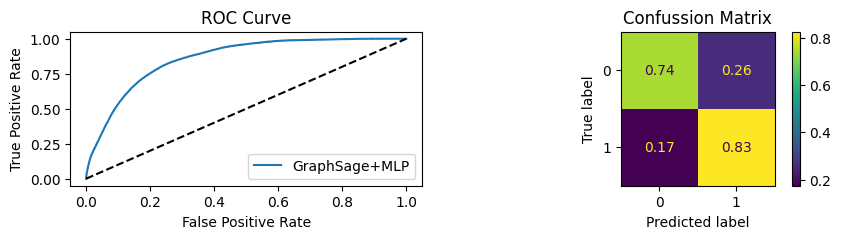
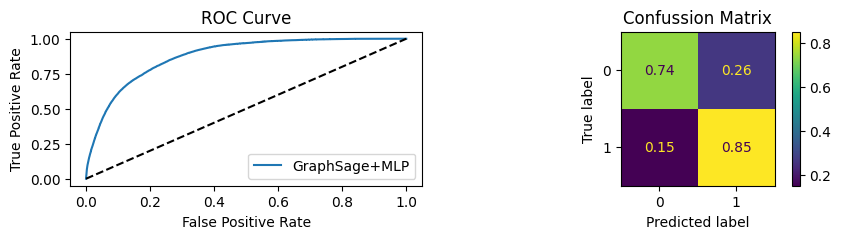
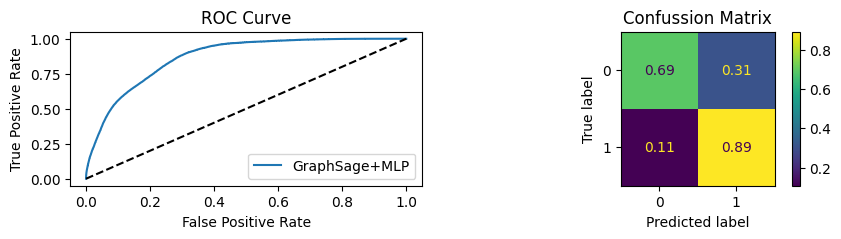
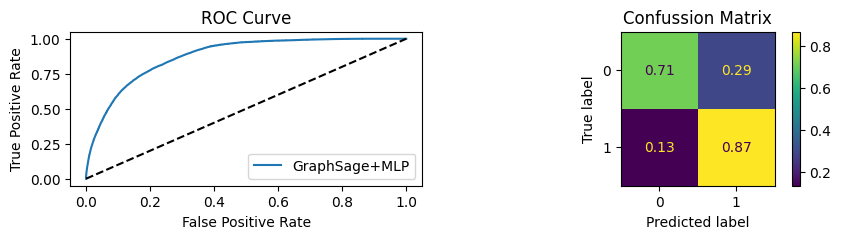
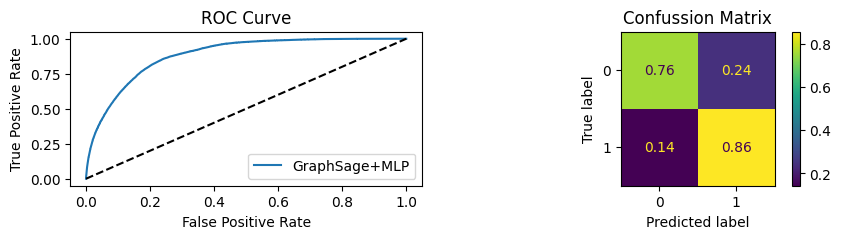
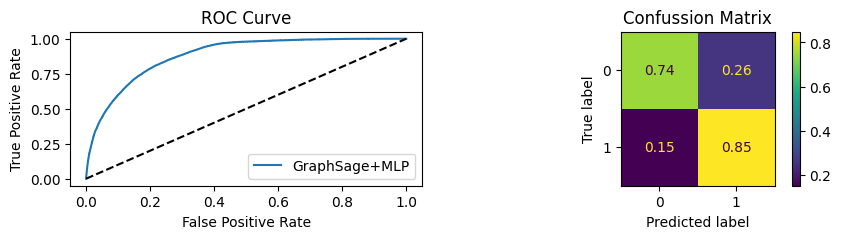
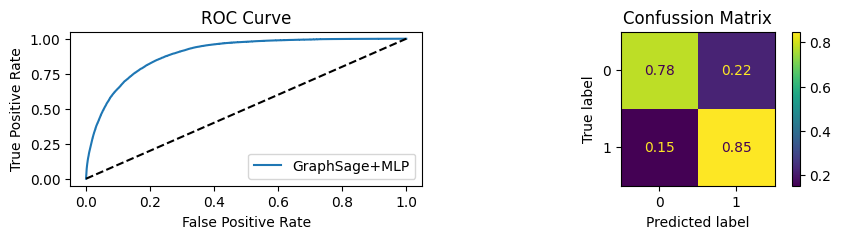
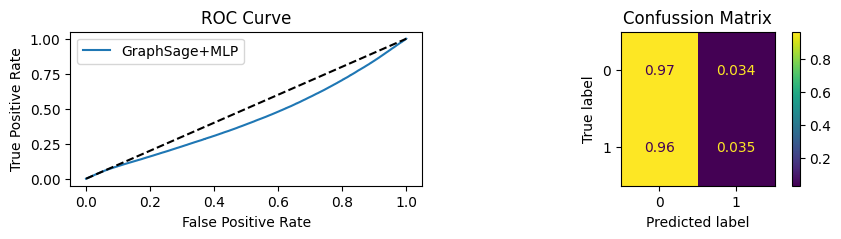
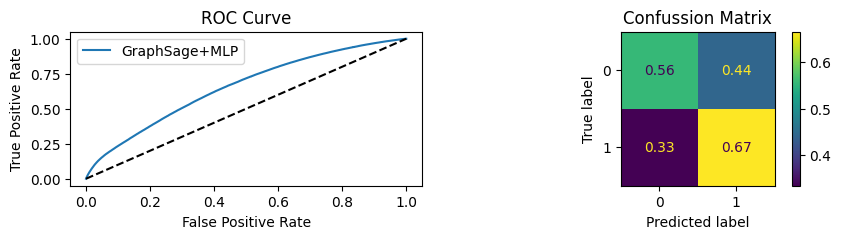
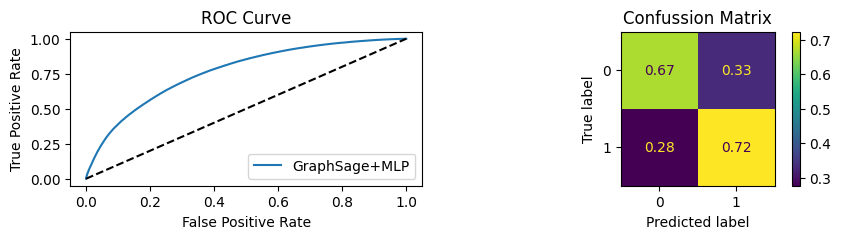
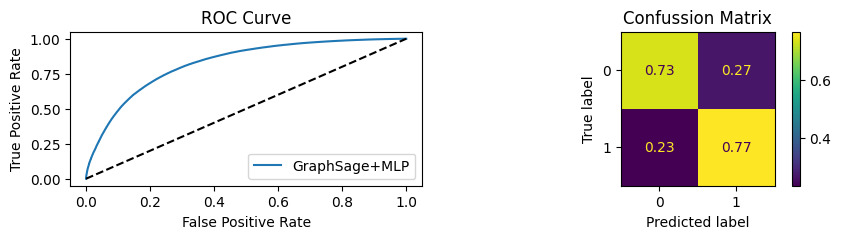
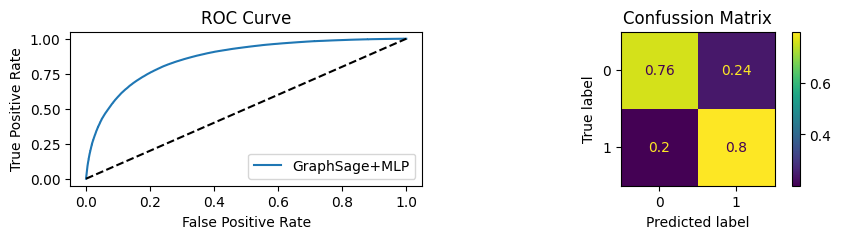
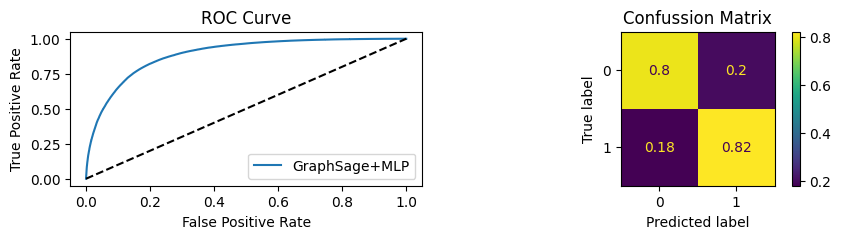
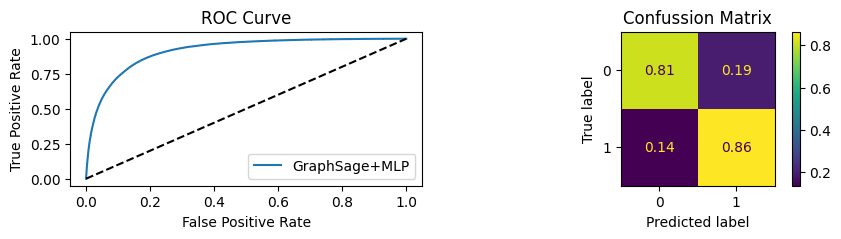
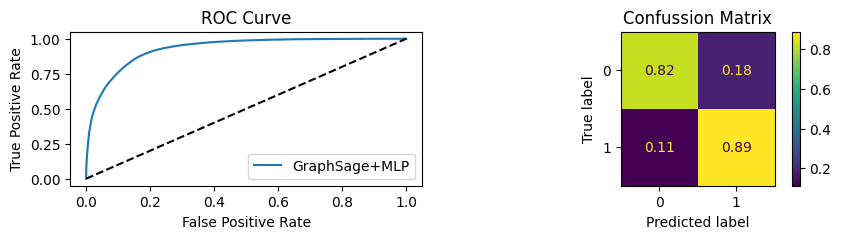
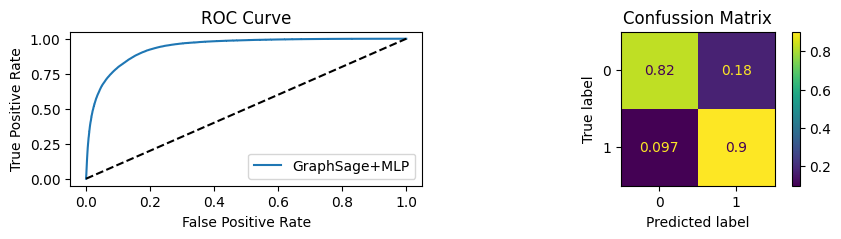
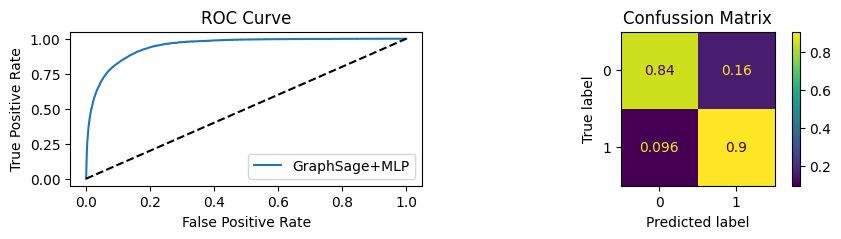
for i in [0.01, 0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]:print(f"Evaluating Model with {i*100}% of PPI's") evaluate(model, link_predictor ,test_loader,device=device,ppi_=i,verbose=True,show_extra_metrics=True)print()
Evaluating Model with 1.0% of PPI's
371 Positive Protein Interactions were used to Embed a graph with 37140 ppi's
149 Positive Protein Interactions were used to Embed a graph with 14908 ppi's
284 Positive Protein Interactions were used to Embed a graph with 28466 ppi's
150 Positive Protein Interactions were used to Embed a graph with 15022 ppi's
172 Positive Protein Interactions were used to Embed a graph with 17228 ppi's
261 Positive Protein Interactions were used to Embed a graph with 26124 ppi's
52 Positive Protein Interactions were used to Embed a graph with 5284 ppi's
63 Positive Protein Interactions were used to Embed a graph with 6366 ppi's
148 Positive Protein Interactions were used to Embed a graph with 14870 ppi's
79 Positive Protein Interactions were used to Embed a graph with 7918 ppi's
Youdens index: 0.7248 Sensitivity: 0.035 Specificity: 0.9659
Evaluating Model with 10.0% of PPI's
3714 Positive Protein Interactions were used to Embed a graph with 37140 ppi's
1490 Positive Protein Interactions were used to Embed a graph with 14908 ppi's
2846 Positive Protein Interactions were used to Embed a graph with 28466 ppi's
1502 Positive Protein Interactions were used to Embed a graph with 15022 ppi's
1722 Positive Protein Interactions were used to Embed a graph with 17228 ppi's
2612 Positive Protein Interactions were used to Embed a graph with 26124 ppi's
528 Positive Protein Interactions were used to Embed a graph with 5284 ppi's
636 Positive Protein Interactions were used to Embed a graph with 6366 ppi's
1487 Positive Protein Interactions were used to Embed a graph with 14870 ppi's
791 Positive Protein Interactions were used to Embed a graph with 7918 ppi's
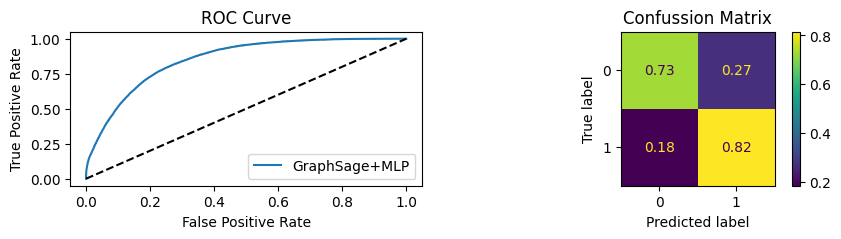
Youdens index: 0.0496 Sensitivity: 0.6652 Specificity: 0.5561
Evaluating Model with 20.0% of PPI's
7428 Positive Protein Interactions were used to Embed a graph with 37140 ppi's
2981 Positive Protein Interactions were used to Embed a graph with 14908 ppi's
5693 Positive Protein Interactions were used to Embed a graph with 28466 ppi's
3004 Positive Protein Interactions were used to Embed a graph with 15022 ppi's
3445 Positive Protein Interactions were used to Embed a graph with 17228 ppi's
5224 Positive Protein Interactions were used to Embed a graph with 26124 ppi's
1056 Positive Protein Interactions were used to Embed a graph with 5284 ppi's
1273 Positive Protein Interactions were used to Embed a graph with 6366 ppi's
2974 Positive Protein Interactions were used to Embed a graph with 14870 ppi's
1583 Positive Protein Interactions were used to Embed a graph with 7918 ppi's
Youdens index: 0.1124 Sensitivity: 0.7235 Specificity: 0.6677
Evaluating Model with 30.0% of PPI's
11142 Positive Protein Interactions were used to Embed a graph with 37140 ppi's
4472 Positive Protein Interactions were used to Embed a graph with 14908 ppi's
8539 Positive Protein Interactions were used to Embed a graph with 28466 ppi's
4506 Positive Protein Interactions were used to Embed a graph with 15022 ppi's
5168 Positive Protein Interactions were used to Embed a graph with 17228 ppi's
7837 Positive Protein Interactions were used to Embed a graph with 26124 ppi's
1585 Positive Protein Interactions were used to Embed a graph with 5284 ppi's
1909 Positive Protein Interactions were used to Embed a graph with 6366 ppi's
4461 Positive Protein Interactions were used to Embed a graph with 14870 ppi's
2375 Positive Protein Interactions were used to Embed a graph with 7918 ppi's
Youdens index: 0.1843 Sensitivity: 0.7657 Specificity: 0.7335
Evaluating Model with 40.0% of PPI's
14856 Positive Protein Interactions were used to Embed a graph with 37140 ppi's
5963 Positive Protein Interactions were used to Embed a graph with 14908 ppi's
11386 Positive Protein Interactions were used to Embed a graph with 28466 ppi's
6008 Positive Protein Interactions were used to Embed a graph with 15022 ppi's
6891 Positive Protein Interactions were used to Embed a graph with 17228 ppi's
10449 Positive Protein Interactions were used to Embed a graph with 26124 ppi's
2113 Positive Protein Interactions were used to Embed a graph with 5284 ppi's
2546 Positive Protein Interactions were used to Embed a graph with 6366 ppi's
5948 Positive Protein Interactions were used to Embed a graph with 14870 ppi's
3167 Positive Protein Interactions were used to Embed a graph with 7918 ppi's
Youdens index: 0.2490 Sensitivity: 0.7996 Specificity: 0.7621
Evaluating Model with 50.0% of PPI's
18570 Positive Protein Interactions were used to Embed a graph with 37140 ppi's
7454 Positive Protein Interactions were used to Embed a graph with 14908 ppi's
14233 Positive Protein Interactions were used to Embed a graph with 28466 ppi's
7511 Positive Protein Interactions were used to Embed a graph with 15022 ppi's
8614 Positive Protein Interactions were used to Embed a graph with 17228 ppi's
13062 Positive Protein Interactions were used to Embed a graph with 26124 ppi's
2642 Positive Protein Interactions were used to Embed a graph with 5284 ppi's
3183 Positive Protein Interactions were used to Embed a graph with 6366 ppi's
7435 Positive Protein Interactions were used to Embed a graph with 14870 ppi's
3959 Positive Protein Interactions were used to Embed a graph with 7918 ppi's
Youdens index: 0.3517 Sensitivity: 0.8204 Specificity: 0.8012
Evaluating Model with 60.0% of PPI's
22284 Positive Protein Interactions were used to Embed a graph with 37140 ppi's
8944 Positive Protein Interactions were used to Embed a graph with 14908 ppi's
17079 Positive Protein Interactions were used to Embed a graph with 28466 ppi's
9013 Positive Protein Interactions were used to Embed a graph with 15022 ppi's
10336 Positive Protein Interactions were used to Embed a graph with 17228 ppi's
15674 Positive Protein Interactions were used to Embed a graph with 26124 ppi's
3170 Positive Protein Interactions were used to Embed a graph with 5284 ppi's
3819 Positive Protein Interactions were used to Embed a graph with 6366 ppi's
8922 Positive Protein Interactions were used to Embed a graph with 14870 ppi's
4750 Positive Protein Interactions were used to Embed a graph with 7918 ppi's
Youdens index: 0.4110 Sensitivity: 0.8645 Specificity: 0.8101
Evaluating Model with 70.0% of PPI's
25998 Positive Protein Interactions were used to Embed a graph with 37140 ppi's
10435 Positive Protein Interactions were used to Embed a graph with 14908 ppi's
19926 Positive Protein Interactions were used to Embed a graph with 28466 ppi's
10515 Positive Protein Interactions were used to Embed a graph with 15022 ppi's
12059 Positive Protein Interactions were used to Embed a graph with 17228 ppi's
18286 Positive Protein Interactions were used to Embed a graph with 26124 ppi's
3698 Positive Protein Interactions were used to Embed a graph with 5284 ppi's
4456 Positive Protein Interactions were used to Embed a graph with 6366 ppi's
10409 Positive Protein Interactions were used to Embed a graph with 14870 ppi's
5542 Positive Protein Interactions were used to Embed a graph with 7918 ppi's
Youdens index: 0.4037 Sensitivity: 0.8886 Specificity: 0.8195
Evaluating Model with 80.0% of PPI's
29712 Positive Protein Interactions were used to Embed a graph with 37140 ppi's
11926 Positive Protein Interactions were used to Embed a graph with 14908 ppi's
22772 Positive Protein Interactions were used to Embed a graph with 28466 ppi's
12017 Positive Protein Interactions were used to Embed a graph with 15022 ppi's
13782 Positive Protein Interactions were used to Embed a graph with 17228 ppi's
20899 Positive Protein Interactions were used to Embed a graph with 26124 ppi's
4227 Positive Protein Interactions were used to Embed a graph with 5284 ppi's
5092 Positive Protein Interactions were used to Embed a graph with 6366 ppi's
11896 Positive Protein Interactions were used to Embed a graph with 14870 ppi's
6334 Positive Protein Interactions were used to Embed a graph with 7918 ppi's
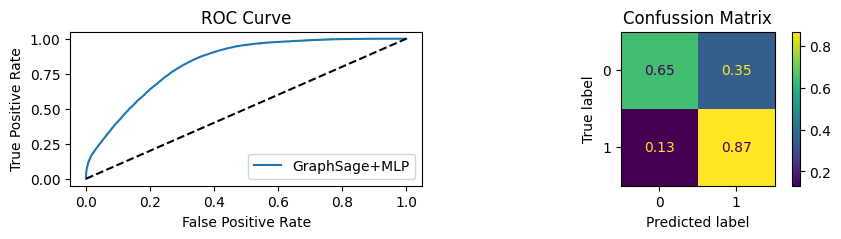
Youdens index: 0.5219 Sensitivity: 0.9028 Specificity: 0.8244
Evaluating Model with 90.0% of PPI's
33426 Positive Protein Interactions were used to Embed a graph with 37140 ppi's
13417 Positive Protein Interactions were used to Embed a graph with 14908 ppi's
25619 Positive Protein Interactions were used to Embed a graph with 28466 ppi's
13519 Positive Protein Interactions were used to Embed a graph with 15022 ppi's
15505 Positive Protein Interactions were used to Embed a graph with 17228 ppi's
23511 Positive Protein Interactions were used to Embed a graph with 26124 ppi's
4755 Positive Protein Interactions were used to Embed a graph with 5284 ppi's
5729 Positive Protein Interactions were used to Embed a graph with 6366 ppi's
13383 Positive Protein Interactions were used to Embed a graph with 14870 ppi's
7126 Positive Protein Interactions were used to Embed a graph with 7918 ppi's
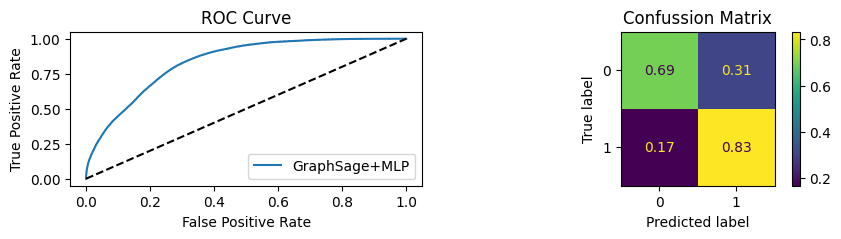
Youdens index: 0.6208 Sensitivity: 0.9041 Specificity: 0.8435
It’s obvious that increaings the PPI percentage the model will learn more and get better accuracy.
Okay! We trained a graph neural network that predict protein-protein interactions!
It’s important to mention two things:
Big part of the code on this post is reused from the work of Perez et al.
Perez et al. also trained a DistMult based prediction model (an a priori model) that doesn’t need graph structure knowledge. I tried to implement this but, due to the small gene set (Unfolded protei binding), this model doesn’t improve larger than 5% percent of accuracy.
Finally, on the next post, I will use this trained model to predict the protein-protein interactions of the proteins expressed by identified genes in a transcriptomic experiment made on Coffea arabica.