Code
from Bio import Entrez, SeqIO
import pandas as pd
import zipfile
import os
import os.path as osp
import io
import numpy as npfrom Bio import Entrez, SeqIO
import pandas as pd
import zipfile
import os
import os.path as osp
import io
import numpy as npThis is the third part of the series using ProtenBERT and Graph neural networks (GNNs). On this part, we’re gonna use the trained model and see if the protein-protein predictions have sense with a specific dataset. The datset we are gonna use comes from a transcriptomic analysis from my thesis (Functional analysis of transcriptomes of Coffea arabica L. related to thermal stress) where I identified genes with high expression that belongs to the Unfolded protein binding gene ontology.
To use the trained model, we need aminoacids sequences which we dont have at the moment. So, first we need to get all the proteins related to the identified genes from the NCBI proteins database.
First, let’s load a csv with the genes:
gene_names_df = pd.read_csv("coffea_arabica_thesis_unfolded_protein_binding.csv", sep=",")
gene_names = list(gene_names_df["gene1"].unique())
gene_names[:5]['LOC113706996',
'LOC113695644',
'LOC113692361',
'LOC113706995',
'LOC113707349']Then, define specific functions to get the protein sequences from NCBI:
def fetch_protein_ids(gene_name):
"""Fetch protein IDs for a given gene name from NCBI."""
handle = Entrez.esearch(db="protein", term=gene_name)
record = Entrez.read(handle)
handle.close()
return record["IdList"]
def fetch_protein_info(protein_id):
"""Fetch protein information for a given protein ID."""
handle = Entrez.efetch(db="protein", id=protein_id, rettype="gb", retmode="text")
record = SeqIO.read(handle, "genbank")
handle.close()
return record
Also, let’s save the aminoacids sequences to a fasta file:
# List to store all protein records
all_protein_records = []
for gene in gene_names:
protein_ids = fetch_protein_ids(gene)
proteins = [fetch_protein_info(pid) for pid in protein_ids]
all_protein_records.extend(proteins)
# Write all protein sequences to a single FASTA file
with open("coffea_arabica_string_protein_sequences.fa", "w") as output_handle:
SeqIO.write(all_protein_records, output_handle, "fasta")
print("All protein sequences have been saved to proteins.fasta")c:\Users\LENOVO\miniconda3\envs\piero\lib\site-packages\Bio\Entrez\__init__.py:723: UserWarning:
Email address is not specified.
To make use of NCBI's E-utilities, NCBI requires you to specify your
email address with each request. As an example, if your email address
is A.N.Other@example.com, you can specify it as follows:
from Bio import Entrez
Entrez.email = 'A.N.Other@example.com'
In case of excessive usage of the E-utilities, NCBI will attempt to contact
a user at the email address provided before blocking access to the
E-utilities.
warnings.warn(All protein sequences have been saved to proteins.fastaOnce we have the fasta file with all the proteins related to those genes, we need to create an interaction dataframe where we have all the possible pairwise interactions between these proteins. And , save those in a tsv file.
import csv
from Bio import SeqIO
from itertools import combinations
# Read protein sequences from the FASTA file
fasta_file = "coffea_arabica_string_protein_sequences.fa"
protein_ids = [record.id for record in SeqIO.parse(fasta_file, "fasta")]
# Generate all pairwise combinations of protein IDs
pairwise_combinations = combinations(protein_ids, 2)
# Save the pairwise combinations to a CSV file
csv_file = "coffea_arabica_string_interactions.tsv"
with open(csv_file, mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow(["Protein1", "Protein2"]) # Write header
for protein1, protein2 in pairwise_combinations:
writer.writerow([protein1, protein2])
print(f"Pairwise combinations saved to {csv_file}")Pairwise combinations saved to coffea_arabica_string_interactions.tsvAlso I manually zip the .tsv and the .fasta file.
Now that we have the necesary data to run the model, we need to get the embedding from the aminoacids sequences using ProteinBERT.
from proteinbert import load_pretrained_model
from proteinbert.conv_and_global_attention_model import get_model_with_hidden_layers_as_outputs
import tensorflow as tfLoad the .tsv file:
with zipfile.ZipFile("coffea_arabica_string_interactions.zip", 'r') as z:
file_names = z.namelist()
tsv_files = [file for file in file_names if file.endswith('interactions.tsv')]
for tsv_file in tsv_files:
with z.open(tsv_file) as f:
df = pd.read_csv(f, sep=',')Get the unique protein IDs:
unique_proteins = set(df["Protein1"]).union(set(df["Protein2"]))
# Count the number of unique protein names
num_unique_proteins = len(unique_proteins)
print(f"Number of unique proteins: {num_unique_proteins}")Number of unique proteins: 28Also, read the protein sequences from the fasta file:
def _read_proteins_from_fasta(fasta_file):
protein_dict = {}
for record in SeqIO.parse(fasta_file, "fasta"):
protein_dict[record.id] = str(record.seq)
return protein_dictwith zipfile.ZipFile("coffea_arabica_string_interactions.zip", 'r') as z:
file_names = z.namelist()
tsv_files = [file for file in file_names if file.endswith('protein_sequences.fa')]
for tsv_file in tsv_files:
with z.open(tsv_file) as f:
f_text = io.TextIOWrapper(f)
protein_sequences_dict = _read_proteins_from_fasta(f_text)protein_sequences_dict{'XP_027084939.1': 'MDVRLLGLDAPLVNALHHLIDAADDGDKIANAPTRTYVRDAKAMAATPADVKEYPNSYVFVVDMPGLKSGDIKVQVEDDNVLVVSGERKREEEKEGARYVRMERRVGKFMRKFVLPENANTDAISAVCQDGVLTVTVHKLPPPEPKKPKVVEVKIV',
'XP_027070567.1': 'MALIPKLFGDMLAPSGLSDETKGIVNARVDWKETPEAHVFKVDLPGLKKEEVKIEVEDGRVLAISGEGAAEKEDKNDKWHRVERSRGRFIRKFLLPENAKVEEVKANMEYGVLTVTIPKQEVKKPEVRAIEISG',
'XP_027066556.1': 'MALIPKLFGDMLAPSGLSDETKGMVNARVDWKETPEAHVFKVDLPGLKKEEVKVEVEDGRVLAISGERAAEKEDKNDKWHRVERSRGRFTRKFLLPENAKXEEVKANMEYGVLTVTIPKQEVKKPEVRAIEISG',
'XP_027084938.1': 'MDVRLLGLDAPLVNALHHLIDAADDGDKIANAPTRTYVRDAKAMAATPADVKEYPNSYVFVVDMPGLKSGDIKVQVEDDNVLVVSGERKREEEKEGARYVRMERRVSKFMRKFVLPENANTDAISAVCQDGVLTVTVHKLPPPEPKKPKVVEVKIA',
'XP_027085429.1': 'MDVRLLGLDAPLVNALHHLIDAADDGDKIANAPTRTYVRDAKAMAATPADVKEYPNSYVFIVDMPGLKSGDIKVQVEDDNVLVVSGERKRAEEKEGARYVRMERRVGKFMRKFVLPENANTDAISAVCQDGVLTVTVHKLPPPEPKKPKVIEVKIV',
'XP_027084168.1': 'MDVRLMGWDTPLFQTIQHMMDATDDADKTVNAPSRTYVRDTKAMASTPADVKEYPNSYAFIVDMPGLKSGDIKVQVEEDNVLIISGERKREEEKEGAKYVRMERRVGKFMRKFVLPENANTDAISAVCQDGVLTVTVQKLPPPEPKKAKTIQVQIA',
'XP_027089120.1': 'MSLIPSFFGNRRSSIFDPFPSDVWDPFRDISLPSSFSGETSSFVIARVDWKETPEAHVFKADLPGIKKEEVKVEVDDDRVLQIRGERNVEKEDKNDTWHRVERSSGQFMRRFRLPENAKMDQIKAAMENGVLTITIPKEEAKKTDVKAIQISG',
'XP_027098388.1': 'MSLIPSVFGGRRSNVFDPFSLDIWDPFEGFPFSNTSLANVPDTARDTSAFATARIDWKETPEAHVFKADLPGLKKEEVKVEVEEGQVLQISGERSREQEEKNDKWHRVERSSGRFLRRFRLPENAKVDQVKASMENGVLTVTVPKEEVKKADVKAIEISG',
'XP_027110885.1': 'MSLIPSIFGGRRSNVFDPFSLDIWDSFPFSDASLANVPNTARETSAFASARIDWKETPEAHVFKADLPGLKKEEVKVEVEDGRVLQISGERSREQEEKNDKWHRIERSSGKFLRRFRLPENAKLDQVKAGMENGVLTITVPKEQVKKPGVKAIEISG',
'XP_027096450.1': 'MSLIPSVFGGRRSNVFDPFSLDIWDPFEGFPFSNTSLANVPDTARDTSAFATARIDWKETPEAHVFKADLPGLKKEEVKVEVEEGRVLQISGERSREQEEKNDKWHRVERSSGRFLRRFRLPENAKVDQVKASMENGVLTVTVPKEEVKKSDVKAIEISG',
'XP_027113320.1': 'MVKATRFVFMSLLVLAAVAALLPEQAEALMPYSPRSFWDMMLPNEDPFRILEHSPLTVPKGVETLALARADWKETAKEHVISLDVPGIKKEEVKIEVEDNRVLRVSGERKTEEEVEGDTWHRAERTVGKFWRQFRLPGNADLDKVQAHLENGVLEIVVPKLAGEKKKQPKVISIAEEAGSNTGVDVKAQRDEM',
'XP_027109657.1': 'MSLIPSFFGNRRSSIFDPFPSDVWDPFRDISLPSSFAGETSSFVNARVDWKETPEAHVFKADLPGIKKEEVKVEVEDDRVLQIRGERNVEKEDKNDTWHRVERSSGQFMRRFRLPENAKMDQIKAAMENGVLTITIPKEEAKKTDVRAIQISG',
'XP_027084891.1': 'MDVRLMGWDTPLFQTIQHMMDAADDADKTVNAPSRTFVRDAKAMASTPADVKEYPNSYAFIVDMPGLKSGDIKVQVEEDNVLIISGERKREEEKEGAKYVRMERRVGKFMRKFALPENANTDAISAVCQDGVLTVTVQKLPPPEPKKAKTIQVQIA',
'XP_027110886.1': 'MALVPSIFGGRRSNIFDPFSLDIWDPFEGFPFSRTLANFPSGTDRETAVFTNARVDWRETPEAHIVQADLPGLKKEEVKVEVEDGRILKISGERSREQEEKTDTWHRVERSSGKFIRSFRMPENAKTEEIKASMENGVLTVTVPKVEEKKPEVKAIKISG',
'XP_027121387.1': 'MALARLALKNLQQRVAPASSSLPSFQCASERTVNSVQKRRWGSELLRRISSAAGKEDSAGQQVAVSEGGKKSNKLFPKKKQRSSLWKKEDDNYPPPLWEFFPSGLGNSLVQASENINRLLGNLSPSRLLGKFKEQDDLYKLRLPVPGLAKEDVKVTVDDGVLTIKGERKEEEEGSDEDDHWASFYGYYNTSVLLPDDAKVDEIRAEMKDGVLTVVIPRTDRPKKDVKEISVH',
'XP_027084272.1': 'MRWEIRSKSCIDHFLMRWEVRSKSCLPSLTTKCDKLLQVVSRRVHSFEPLGMDLRNLGMDIGGMGFGIDNPILSTIQDMLELSEEHDKGNQNNPSRAYVRDAKAMARTPADIKEYPDSYALVVDMPGIKANEIKVQVEDDNVLVVSGERKREKEEGVKYLKMERRGGKSMRKFVLPENANLDAISAVSRDGVLTVTVQKFPPPQAKKHKTIEVKAG',
'XP_027122722.1': 'MSTVVEAINHLFNFPETLDKFMLNSSSRAGEGAGSVANDSRGGVGSLPAVDILDSPKAYVFYVDVPGLSKSDIQVTLEDENTLVIRSNGKRKREDGEEEGCKYIRLERSAPQKLSRKFRLPDNANASAISANCENGVLTVAVEKLPPPPKSKTVQVAIS',
'XP_027125186.1': 'MSTVVEAINHLFNFPETLDKFLLNSSSRAGEGAGSVANDSRGGVGSLPAVDILDSPKAYVFYVDVPGLSKSDIQVTLEDENTLVIRSNGKRKREDGEEEGCKYIRLERSAPQKLSRKFRLPDNANASAISANCENGVLTVAVEKLPPPPKSKTVQVAIS',
'XP_027089887.1': 'MSVFPLQSMLLNTFSSESSCCSMDWKETPEAHVFKFDLPGLTKEDVKVQIHDNQVLHLSADRKDEDNQETGESDDRKRGGGGGGEYKWHCKERICGGSFQREFRLPEDALVDQIKASMSDGVLVVTVPKDHHLKKKKLKHGAVEISGVDGRNDAFSPKGFVRFVCCKA',
'XP_027074077.1': 'MALFGDPFRRFFWSPTIYRTSPGSSALLDWIESPDAHIFKINVPGFSKDEIKVQVEEGNVLVIKAEAKEEGGGQGKEKDVVWHVAERGGGITGKAAGFSREIELPEDVKADQIRASVENGVLTVVVPKDTTPKSSKVRNVNVTSKL',
'XP_027077852.1': 'MALFGDPFRRFFWSPTIYRTSPGSSALLDWIESPDAHIFKINVPGFSKDEIKVQVEEGNVLVIKAEAKEEGGGQGKEKDVVWHVAERGGGITGKAAGFSREIELPEDVKADQIRASVENGVLTVVVPKDTTPKSSKVRNVNVTSKL',
'XP_027108429.1': 'MITLVMFILWTSLLSDYKYQSLNPPFSSTSNRKQYQFLPVQLILAFELSLLGHILHTTKMSLIPSFFGGRKTNVFDPFSLDIWDPFDGFFVTSPSVANWPSSARETAAVATARIDWKETPEAHVFKADVPGLKKEELKVEVEEGRILQISGERSKEQEEKNDKWHRSERRRGKFLRRFRLPENAKVEEVKASLEDGVLTVTVPKVEEKKPEVKSIEISA',
'XP_027105380.1': 'MGVDYYKILQVDKSAKDEDLKKAYRKLAMKWHPDKNPNNKKEAEAKFKQISEAYEVLSDPEKRAIYDQYGEEGLKGQVPPPGAGGPGRATFFQTGDGPNVFRFNPRNANDIFDEFFGFSTPFGGMGGAGGMNGGGTRFPSSMFGDDIFSSFGEGRTMNSVPWKAPPIEQNLPCSLEELSKGTTKKMKISREIADASGKTLPVQEILTIDIKPGWKKGTKITFPEKGNEQPNVIPSDLVFIIDEKPHSVFKRDGNDLVVTQKISLAEALTGCTVHLTTLDGRKLTVPINAPIHPDYEEVVPREGMPIPKEPSKRGNLRIKFNIKFPTGLTAEQKSGIKKLLSP',
'XP_027063211.1': 'MITLVMFILWTSLLSDYKYQSLNPPFSSTSNRKRYQFLPVQLILAFELSLLGHILHTTKMSLIPSFFGGRKTNVFDPFSLDIWDPFDGFFVTSPSVANWPSSARETAAFATARIDWKETPEAHVFKADVPGLKKEELKVEVEEGRILQISGERSKEQEEKNDKWYRSERSSGKFLRRFRLPENAKVEEVKASLEDGVLTVTVPKVEEKKPEVKSIEISA',
'XP_027062161.1': 'MGLDYYKILGVDKKATDDDMKKAYRKLAMKWHPDKNPNNKKDAEAKFKQISEAYDVLSDPQKRAVYDQYGEEGLKAGVPPPDTAGGPGGTTFFSTGGGPTSFRFNPRSPDDIFSEIFGFSGFGGMGGGSGMRGSRFGGMFDDSMFSSFEGGGSGPGGSMHQQAIRKAPAIEQNLPCTLEELYKGTTKKMKISREVLDTNSGKIMPVEEILTINIKPGWKKGTKITFPDKGNELPGVAPADLVFIIDEKPHRVFTREGNDLIVTQKVSLTEALTGYTAHLTTLDGRNLTIPVTSVIHPTYEEVVRGEGMPLPKDPSKKGNLRIKFDIKFPARLTASQKAGIKELLGS',
'XP_027110883.1': 'MSMVPSFFGRRSSTPDEIWDPFQGWPFNSDFSPFSGQLRTTFPSSSSETASFAHASIDWKETPNAHVFKADVPGLRKEEVKVEVEDERILQISGERKREIEDKGHTWHKVERSSGKFMRRFRLPENAKVEQVKASMENGVLTVTVPKAEIRKPDVKSIEISG',
'XP_027065019.1': 'MGLDYYKILGVDKKATDDDMKKAYRKLAMKWHPDKNPNNKKDAEAKFKQISEAYDVLSDPQKRAVYDQYGEEGLKGGVPPPDTAGGPGSATFFSTGGGPTSFRFNPRSPDDIFSEIFGFSGFGGMGGGSGMRGSRFGGMFDDSMFSSFEGGGSGPGGSMHQQTIRKAPAIEQNLPCTLEELYKGTTKKMKISREVLDTNSGKIMPVEEILTINIKPGWKKGTKITFPDKGNELPGVAPADLVFIIDEKPHRVFTREGNDLIVTQKVSLTEALTGYTAHLTTLDGRNLTIPVTSVIHPTYEEVVRGEGMPLPKDPSKKGNLRIKFDIKFPARLTASQKAGIKELLGS',
'XP_027095883.1': 'MSLIPSVFGGRRSNVFDPFSLDIWDPFEGFPFSNTSLANVPDTARDTSAFATARIDWKETPEAHVFKADLPGLKKEEVKVEVEEGRVLQISGERSREQEEKNDKWHRVERSSGRFLRRFRLPENAKVDQVKASMENGVLTVTVPKEEVKKSDVKAIEISG'}unique_proteins = set(df['Protein1']).union(set(df['Protein2']))This is to mbe sure that we have all the aminoacids sequences that are avaialble on the .tsv file:
filtered_protein_dict = {protein: seq for protein, seq in protein_sequences_dict.items() if protein in unique_proteins}
filtered_protein_dict{'XP_027084939.1': 'MDVRLLGLDAPLVNALHHLIDAADDGDKIANAPTRTYVRDAKAMAATPADVKEYPNSYVFVVDMPGLKSGDIKVQVEDDNVLVVSGERKREEEKEGARYVRMERRVGKFMRKFVLPENANTDAISAVCQDGVLTVTVHKLPPPEPKKPKVVEVKIV',
'XP_027070567.1': 'MALIPKLFGDMLAPSGLSDETKGIVNARVDWKETPEAHVFKVDLPGLKKEEVKIEVEDGRVLAISGEGAAEKEDKNDKWHRVERSRGRFIRKFLLPENAKVEEVKANMEYGVLTVTIPKQEVKKPEVRAIEISG',
'XP_027066556.1': 'MALIPKLFGDMLAPSGLSDETKGMVNARVDWKETPEAHVFKVDLPGLKKEEVKVEVEDGRVLAISGERAAEKEDKNDKWHRVERSRGRFTRKFLLPENAKXEEVKANMEYGVLTVTIPKQEVKKPEVRAIEISG',
'XP_027084938.1': 'MDVRLLGLDAPLVNALHHLIDAADDGDKIANAPTRTYVRDAKAMAATPADVKEYPNSYVFVVDMPGLKSGDIKVQVEDDNVLVVSGERKREEEKEGARYVRMERRVSKFMRKFVLPENANTDAISAVCQDGVLTVTVHKLPPPEPKKPKVVEVKIA',
'XP_027085429.1': 'MDVRLLGLDAPLVNALHHLIDAADDGDKIANAPTRTYVRDAKAMAATPADVKEYPNSYVFIVDMPGLKSGDIKVQVEDDNVLVVSGERKRAEEKEGARYVRMERRVGKFMRKFVLPENANTDAISAVCQDGVLTVTVHKLPPPEPKKPKVIEVKIV',
'XP_027084168.1': 'MDVRLMGWDTPLFQTIQHMMDATDDADKTVNAPSRTYVRDTKAMASTPADVKEYPNSYAFIVDMPGLKSGDIKVQVEEDNVLIISGERKREEEKEGAKYVRMERRVGKFMRKFVLPENANTDAISAVCQDGVLTVTVQKLPPPEPKKAKTIQVQIA',
'XP_027089120.1': 'MSLIPSFFGNRRSSIFDPFPSDVWDPFRDISLPSSFSGETSSFVIARVDWKETPEAHVFKADLPGIKKEEVKVEVDDDRVLQIRGERNVEKEDKNDTWHRVERSSGQFMRRFRLPENAKMDQIKAAMENGVLTITIPKEEAKKTDVKAIQISG',
'XP_027098388.1': 'MSLIPSVFGGRRSNVFDPFSLDIWDPFEGFPFSNTSLANVPDTARDTSAFATARIDWKETPEAHVFKADLPGLKKEEVKVEVEEGQVLQISGERSREQEEKNDKWHRVERSSGRFLRRFRLPENAKVDQVKASMENGVLTVTVPKEEVKKADVKAIEISG',
'XP_027110885.1': 'MSLIPSIFGGRRSNVFDPFSLDIWDSFPFSDASLANVPNTARETSAFASARIDWKETPEAHVFKADLPGLKKEEVKVEVEDGRVLQISGERSREQEEKNDKWHRIERSSGKFLRRFRLPENAKLDQVKAGMENGVLTITVPKEQVKKPGVKAIEISG',
'XP_027096450.1': 'MSLIPSVFGGRRSNVFDPFSLDIWDPFEGFPFSNTSLANVPDTARDTSAFATARIDWKETPEAHVFKADLPGLKKEEVKVEVEEGRVLQISGERSREQEEKNDKWHRVERSSGRFLRRFRLPENAKVDQVKASMENGVLTVTVPKEEVKKSDVKAIEISG',
'XP_027113320.1': 'MVKATRFVFMSLLVLAAVAALLPEQAEALMPYSPRSFWDMMLPNEDPFRILEHSPLTVPKGVETLALARADWKETAKEHVISLDVPGIKKEEVKIEVEDNRVLRVSGERKTEEEVEGDTWHRAERTVGKFWRQFRLPGNADLDKVQAHLENGVLEIVVPKLAGEKKKQPKVISIAEEAGSNTGVDVKAQRDEM',
'XP_027109657.1': 'MSLIPSFFGNRRSSIFDPFPSDVWDPFRDISLPSSFAGETSSFVNARVDWKETPEAHVFKADLPGIKKEEVKVEVEDDRVLQIRGERNVEKEDKNDTWHRVERSSGQFMRRFRLPENAKMDQIKAAMENGVLTITIPKEEAKKTDVRAIQISG',
'XP_027084891.1': 'MDVRLMGWDTPLFQTIQHMMDAADDADKTVNAPSRTFVRDAKAMASTPADVKEYPNSYAFIVDMPGLKSGDIKVQVEEDNVLIISGERKREEEKEGAKYVRMERRVGKFMRKFALPENANTDAISAVCQDGVLTVTVQKLPPPEPKKAKTIQVQIA',
'XP_027110886.1': 'MALVPSIFGGRRSNIFDPFSLDIWDPFEGFPFSRTLANFPSGTDRETAVFTNARVDWRETPEAHIVQADLPGLKKEEVKVEVEDGRILKISGERSREQEEKTDTWHRVERSSGKFIRSFRMPENAKTEEIKASMENGVLTVTVPKVEEKKPEVKAIKISG',
'XP_027121387.1': 'MALARLALKNLQQRVAPASSSLPSFQCASERTVNSVQKRRWGSELLRRISSAAGKEDSAGQQVAVSEGGKKSNKLFPKKKQRSSLWKKEDDNYPPPLWEFFPSGLGNSLVQASENINRLLGNLSPSRLLGKFKEQDDLYKLRLPVPGLAKEDVKVTVDDGVLTIKGERKEEEEGSDEDDHWASFYGYYNTSVLLPDDAKVDEIRAEMKDGVLTVVIPRTDRPKKDVKEISVH',
'XP_027084272.1': 'MRWEIRSKSCIDHFLMRWEVRSKSCLPSLTTKCDKLLQVVSRRVHSFEPLGMDLRNLGMDIGGMGFGIDNPILSTIQDMLELSEEHDKGNQNNPSRAYVRDAKAMARTPADIKEYPDSYALVVDMPGIKANEIKVQVEDDNVLVVSGERKREKEEGVKYLKMERRGGKSMRKFVLPENANLDAISAVSRDGVLTVTVQKFPPPQAKKHKTIEVKAG',
'XP_027122722.1': 'MSTVVEAINHLFNFPETLDKFMLNSSSRAGEGAGSVANDSRGGVGSLPAVDILDSPKAYVFYVDVPGLSKSDIQVTLEDENTLVIRSNGKRKREDGEEEGCKYIRLERSAPQKLSRKFRLPDNANASAISANCENGVLTVAVEKLPPPPKSKTVQVAIS',
'XP_027125186.1': 'MSTVVEAINHLFNFPETLDKFLLNSSSRAGEGAGSVANDSRGGVGSLPAVDILDSPKAYVFYVDVPGLSKSDIQVTLEDENTLVIRSNGKRKREDGEEEGCKYIRLERSAPQKLSRKFRLPDNANASAISANCENGVLTVAVEKLPPPPKSKTVQVAIS',
'XP_027089887.1': 'MSVFPLQSMLLNTFSSESSCCSMDWKETPEAHVFKFDLPGLTKEDVKVQIHDNQVLHLSADRKDEDNQETGESDDRKRGGGGGGEYKWHCKERICGGSFQREFRLPEDALVDQIKASMSDGVLVVTVPKDHHLKKKKLKHGAVEISGVDGRNDAFSPKGFVRFVCCKA',
'XP_027074077.1': 'MALFGDPFRRFFWSPTIYRTSPGSSALLDWIESPDAHIFKINVPGFSKDEIKVQVEEGNVLVIKAEAKEEGGGQGKEKDVVWHVAERGGGITGKAAGFSREIELPEDVKADQIRASVENGVLTVVVPKDTTPKSSKVRNVNVTSKL',
'XP_027077852.1': 'MALFGDPFRRFFWSPTIYRTSPGSSALLDWIESPDAHIFKINVPGFSKDEIKVQVEEGNVLVIKAEAKEEGGGQGKEKDVVWHVAERGGGITGKAAGFSREIELPEDVKADQIRASVENGVLTVVVPKDTTPKSSKVRNVNVTSKL',
'XP_027108429.1': 'MITLVMFILWTSLLSDYKYQSLNPPFSSTSNRKQYQFLPVQLILAFELSLLGHILHTTKMSLIPSFFGGRKTNVFDPFSLDIWDPFDGFFVTSPSVANWPSSARETAAVATARIDWKETPEAHVFKADVPGLKKEELKVEVEEGRILQISGERSKEQEEKNDKWHRSERRRGKFLRRFRLPENAKVEEVKASLEDGVLTVTVPKVEEKKPEVKSIEISA',
'XP_027105380.1': 'MGVDYYKILQVDKSAKDEDLKKAYRKLAMKWHPDKNPNNKKEAEAKFKQISEAYEVLSDPEKRAIYDQYGEEGLKGQVPPPGAGGPGRATFFQTGDGPNVFRFNPRNANDIFDEFFGFSTPFGGMGGAGGMNGGGTRFPSSMFGDDIFSSFGEGRTMNSVPWKAPPIEQNLPCSLEELSKGTTKKMKISREIADASGKTLPVQEILTIDIKPGWKKGTKITFPEKGNEQPNVIPSDLVFIIDEKPHSVFKRDGNDLVVTQKISLAEALTGCTVHLTTLDGRKLTVPINAPIHPDYEEVVPREGMPIPKEPSKRGNLRIKFNIKFPTGLTAEQKSGIKKLLSP',
'XP_027063211.1': 'MITLVMFILWTSLLSDYKYQSLNPPFSSTSNRKRYQFLPVQLILAFELSLLGHILHTTKMSLIPSFFGGRKTNVFDPFSLDIWDPFDGFFVTSPSVANWPSSARETAAFATARIDWKETPEAHVFKADVPGLKKEELKVEVEEGRILQISGERSKEQEEKNDKWYRSERSSGKFLRRFRLPENAKVEEVKASLEDGVLTVTVPKVEEKKPEVKSIEISA',
'XP_027062161.1': 'MGLDYYKILGVDKKATDDDMKKAYRKLAMKWHPDKNPNNKKDAEAKFKQISEAYDVLSDPQKRAVYDQYGEEGLKAGVPPPDTAGGPGGTTFFSTGGGPTSFRFNPRSPDDIFSEIFGFSGFGGMGGGSGMRGSRFGGMFDDSMFSSFEGGGSGPGGSMHQQAIRKAPAIEQNLPCTLEELYKGTTKKMKISREVLDTNSGKIMPVEEILTINIKPGWKKGTKITFPDKGNELPGVAPADLVFIIDEKPHRVFTREGNDLIVTQKVSLTEALTGYTAHLTTLDGRNLTIPVTSVIHPTYEEVVRGEGMPLPKDPSKKGNLRIKFDIKFPARLTASQKAGIKELLGS',
'XP_027110883.1': 'MSMVPSFFGRRSSTPDEIWDPFQGWPFNSDFSPFSGQLRTTFPSSSSETASFAHASIDWKETPNAHVFKADVPGLRKEEVKVEVEDERILQISGERKREIEDKGHTWHKVERSSGKFMRRFRLPENAKVEQVKASMENGVLTVTVPKAEIRKPDVKSIEISG',
'XP_027065019.1': 'MGLDYYKILGVDKKATDDDMKKAYRKLAMKWHPDKNPNNKKDAEAKFKQISEAYDVLSDPQKRAVYDQYGEEGLKGGVPPPDTAGGPGSATFFSTGGGPTSFRFNPRSPDDIFSEIFGFSGFGGMGGGSGMRGSRFGGMFDDSMFSSFEGGGSGPGGSMHQQTIRKAPAIEQNLPCTLEELYKGTTKKMKISREVLDTNSGKIMPVEEILTINIKPGWKKGTKITFPDKGNELPGVAPADLVFIIDEKPHRVFTREGNDLIVTQKVSLTEALTGYTAHLTTLDGRNLTIPVTSVIHPTYEEVVRGEGMPLPKDPSKKGNLRIKFDIKFPARLTASQKAGIKELLGS',
'XP_027095883.1': 'MSLIPSVFGGRRSNVFDPFSLDIWDPFEGFPFSNTSLANVPDTARDTSAFATARIDWKETPEAHVFKADLPGLKKEEVKVEVEEGRVLQISGERSREQEEKNDKWHRVERSSGRFLRRFRLPENAKVDQVKASMENGVLTVTVPKEEVKKSDVKAIEISG'}To run ProteinBERT, we need to get the longest sequence:
sequences = list(filtered_protein_dict.values())
longest_sequence_length = max(len(seq) for seq in sequences)
longest_sequence_length346seq_len = longest_sequence_length+2
global_embeds = []
local_embeds = []
batch_size = 2Let’s define a function that helps us get the embeddings:
def _get_embeddings(seq, seq_len=512, batch_size=1):
pretrained_model_generator, input_encoder = load_pretrained_model()
model = get_model_with_hidden_layers_as_outputs(pretrained_model_generator.create_model(seq_len=seq_len))
encoded_x = input_encoder.encode_X(seq, seq_len)
local_representations, global_representations = model.predict(encoded_x, batch_size=batch_size)
return local_representations, global_representationsAnd use it for all the proteins:
for i in range(0, len(sequences), batch_size):
batch_seqs = sequences[i:i + batch_size]
local_representation, global_representation = _get_embeddings(batch_seqs, seq_len=seq_len, batch_size=batch_size)
global_embeds.extend(global_representation)
local_embeds.extend(local_representation)
global_embeds = np.array(global_embeds)
local_embeds = np.array(local_embeds)WARNING:tensorflow:From c:\Users\LENOVO\miniconda3\envs\piero\lib\site-packages\keras-3.3.3-py3.10.egg\keras\src\backend\common\global_state.py:82: The name tf.reset_default_graph is deprecated. Please use tf.compat.v1.reset_default_graph instead. 1/1 ━━━━━━━━━━━━━━━━━━━━ 2s 2s/step 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step WARNING:tensorflow:5 out of the last 5 calls to <function TensorFlowTrainer.make_predict_function.<locals>.one_step_on_data_distributed at 0x0000029623428EE0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details. 1/1 ━━━━━━━━━━━━━━━━━━━━ 2s 2s/step WARNING:tensorflow:6 out of the last 6 calls to <function TensorFlowTrainer.make_predict_function.<locals>.one_step_on_data_distributed at 0x0000029623444EE0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details. 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 1s/step
print(global_embeds.shape)
print(global_embeds.shape)(28, 15599)
(28, 15599)Now that we have the embedings, we need to create the edge_index to create a pytorch geometric Data object.
First, we need to encode the protein ID’s:
from sklearn import model_selection, metrics, preprocessing
unique_proteins_set = set(df["Protein1"]).union(set(df["Protein2"]))
all_proteins = list(unique_proteins_set)
print(f"All unique proteins: {all_proteins}")
num_unique_proteins = len(all_proteins)
print(f"Number of unique proteins: {num_unique_proteins}")
print(f"Unique proteins: {all_proteins}")
# Fit the LabelEncoder on all unique proteins
lbl_protein = preprocessing.LabelEncoder()
lbl_protein.fit(all_proteins)
# Verify the number of classes
num_classes = len(lbl_protein.classes_)
print(f"Number of classes in LabelEncoder: {num_classes}")
print(f"Classes: {lbl_protein.classes_}")
# Check if there is any discrepancy
if num_classes != num_unique_proteins:
missing_proteins = unique_proteins_set - set(lbl_protein.classes_)
print(f"Missing proteins in LabelEncoder: {missing_proteins}")All unique proteins: ['XP_027110886.1', 'XP_027089887.1', 'XP_027089120.1', 'XP_027110885.1', 'XP_027110883.1', 'XP_027077852.1', 'XP_027098388.1', 'XP_027074077.1', 'XP_027084168.1', 'XP_027113320.1', 'XP_027065019.1', 'XP_027084891.1', 'XP_027095883.1', 'XP_027109657.1', 'XP_027096450.1', 'XP_027085429.1', 'XP_027084939.1', 'XP_027066556.1', 'XP_027084272.1', 'XP_027084938.1', 'XP_027070567.1', 'XP_027121387.1', 'XP_027108429.1', 'XP_027122722.1', 'XP_027125186.1', 'XP_027062161.1', 'XP_027105380.1', 'XP_027063211.1']
Number of unique proteins: 28
Unique proteins: ['XP_027110886.1', 'XP_027089887.1', 'XP_027089120.1', 'XP_027110885.1', 'XP_027110883.1', 'XP_027077852.1', 'XP_027098388.1', 'XP_027074077.1', 'XP_027084168.1', 'XP_027113320.1', 'XP_027065019.1', 'XP_027084891.1', 'XP_027095883.1', 'XP_027109657.1', 'XP_027096450.1', 'XP_027085429.1', 'XP_027084939.1', 'XP_027066556.1', 'XP_027084272.1', 'XP_027084938.1', 'XP_027070567.1', 'XP_027121387.1', 'XP_027108429.1', 'XP_027122722.1', 'XP_027125186.1', 'XP_027062161.1', 'XP_027105380.1', 'XP_027063211.1']
Number of classes in LabelEncoder: 28
Classes: ['XP_027062161.1' 'XP_027063211.1' 'XP_027065019.1' 'XP_027066556.1'
'XP_027070567.1' 'XP_027074077.1' 'XP_027077852.1' 'XP_027084168.1'
'XP_027084272.1' 'XP_027084891.1' 'XP_027084938.1' 'XP_027084939.1'
'XP_027085429.1' 'XP_027089120.1' 'XP_027089887.1' 'XP_027095883.1'
'XP_027096450.1' 'XP_027098388.1' 'XP_027105380.1' 'XP_027108429.1'
'XP_027109657.1' 'XP_027110883.1' 'XP_027110885.1' 'XP_027110886.1'
'XP_027113320.1' 'XP_027121387.1' 'XP_027122722.1' 'XP_027125186.1']df["node1_string_id"] = lbl_protein.transform(df.Protein1.values)
df["node2_string_id"] = lbl_protein.transform(df.Protein2.values)
# Verify the transformations
print(f"Transformed Protein1: {df['node1_string_id'].unique()}")
print(f"Transformed Protein2: {df['node2_string_id'].unique()}")Transformed Protein1: [11 4 3 10 12 7 13 17 22 16 24 20 9 23 25 8 26 27 14 5 6 19 18 1
0 21 2]
Transformed Protein2: [ 4 3 10 12 7 13 17 22 16 24 20 9 23 25 8 26 27 14 5 6 19 18 1 0
21 2 15]df| Protein1 | Protein2 | node1_string_id | node2_string_id | |
|---|---|---|---|---|
| 0 | XP_027084939.1 | XP_027070567.1 | 11 | 4 |
| 1 | XP_027084939.1 | XP_027066556.1 | 11 | 3 |
| 2 | XP_027084939.1 | XP_027084938.1 | 11 | 10 |
| 3 | XP_027084939.1 | XP_027085429.1 | 11 | 12 |
| 4 | XP_027084939.1 | XP_027084168.1 | 11 | 7 |
| ... | ... | ... | ... | ... |
| 373 | XP_027062161.1 | XP_027065019.1 | 0 | 2 |
| 374 | XP_027062161.1 | XP_027095883.1 | 0 | 15 |
| 375 | XP_027110883.1 | XP_027065019.1 | 21 | 2 |
| 376 | XP_027110883.1 | XP_027095883.1 | 21 | 15 |
| 377 | XP_027065019.1 | XP_027095883.1 | 2 | 15 |
378 rows × 4 columns
Then, with a helper function create the edge index:
import torch
def _load_edge_csv(df, src_index_col, dst_index_col):
src = df[src_index_col].values
dst = df[dst_index_col].values
edge_index = [src, dst]
return edge_indexedge_index = _load_edge_csv(df=df, src_index_col="node1_string_id", dst_index_col="node2_string_id")
edge_index = torch.LongTensor(edge_index)C:\Users\LENOVO\AppData\Local\Temp\ipykernel_3324\4265644366.py:2: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ..\torch\csrc\utils\tensor_new.cpp:277.)
edge_index = torch.LongTensor(edge_index)edge_indextensor([[11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11,
11, 11, 11, 11, 11, 11, 11, 11, 11, 4, 4, 4, 4, 4, 4, 4, 4, 4,
4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10,
10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 12, 12, 12, 12, 12, 12,
12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13,
13, 13, 13, 13, 13, 13, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17,
17, 17, 17, 17, 17, 17, 17, 17, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22,
22, 22, 22, 22, 22, 22, 22, 22, 22, 16, 16, 16, 16, 16, 16, 16, 16, 16,
16, 16, 16, 16, 16, 16, 16, 16, 16, 24, 24, 24, 24, 24, 24, 24, 24, 24,
24, 24, 24, 24, 24, 24, 24, 24, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20,
20, 20, 20, 20, 20, 20, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9,
9, 9, 9, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 25,
25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 8, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 26, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 14, 14, 14, 14, 14, 14, 14, 14, 14,
5, 5, 5, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 6, 19, 19, 19,
19, 19, 19, 18, 18, 18, 18, 18, 1, 1, 1, 1, 0, 0, 0, 21, 21, 2],
[ 4, 3, 10, 12, 7, 13, 17, 22, 16, 24, 20, 9, 23, 25, 8, 26, 27, 14,
5, 6, 19, 18, 1, 0, 21, 2, 15, 3, 10, 12, 7, 13, 17, 22, 16, 24,
20, 9, 23, 25, 8, 26, 27, 14, 5, 6, 19, 18, 1, 0, 21, 2, 15, 10,
12, 7, 13, 17, 22, 16, 24, 20, 9, 23, 25, 8, 26, 27, 14, 5, 6, 19,
18, 1, 0, 21, 2, 15, 12, 7, 13, 17, 22, 16, 24, 20, 9, 23, 25, 8,
26, 27, 14, 5, 6, 19, 18, 1, 0, 21, 2, 15, 7, 13, 17, 22, 16, 24,
20, 9, 23, 25, 8, 26, 27, 14, 5, 6, 19, 18, 1, 0, 21, 2, 15, 13,
17, 22, 16, 24, 20, 9, 23, 25, 8, 26, 27, 14, 5, 6, 19, 18, 1, 0,
21, 2, 15, 17, 22, 16, 24, 20, 9, 23, 25, 8, 26, 27, 14, 5, 6, 19,
18, 1, 0, 21, 2, 15, 22, 16, 24, 20, 9, 23, 25, 8, 26, 27, 14, 5,
6, 19, 18, 1, 0, 21, 2, 15, 16, 24, 20, 9, 23, 25, 8, 26, 27, 14,
5, 6, 19, 18, 1, 0, 21, 2, 15, 24, 20, 9, 23, 25, 8, 26, 27, 14,
5, 6, 19, 18, 1, 0, 21, 2, 15, 20, 9, 23, 25, 8, 26, 27, 14, 5,
6, 19, 18, 1, 0, 21, 2, 15, 9, 23, 25, 8, 26, 27, 14, 5, 6, 19,
18, 1, 0, 21, 2, 15, 23, 25, 8, 26, 27, 14, 5, 6, 19, 18, 1, 0,
21, 2, 15, 25, 8, 26, 27, 14, 5, 6, 19, 18, 1, 0, 21, 2, 15, 8,
26, 27, 14, 5, 6, 19, 18, 1, 0, 21, 2, 15, 26, 27, 14, 5, 6, 19,
18, 1, 0, 21, 2, 15, 27, 14, 5, 6, 19, 18, 1, 0, 21, 2, 15, 14,
5, 6, 19, 18, 1, 0, 21, 2, 15, 5, 6, 19, 18, 1, 0, 21, 2, 15,
6, 19, 18, 1, 0, 21, 2, 15, 19, 18, 1, 0, 21, 2, 15, 18, 1, 0,
21, 2, 15, 1, 0, 21, 2, 15, 0, 21, 2, 15, 21, 2, 15, 2, 15, 15]])I’m assigning a class to Coffea arabica
y = torch.tensor([61], dtype=torch.long)We have all the necesary to create the Data object:
from torch_geometric.data import Dataset, download_url, extract_zip, Data
global_embeds = torch.tensor(global_embeds, dtype=torch.float)
data = Data(x=global_embeds,edge_index=edge_index, y=y)dataData(x=[28, 15599], edge_index=[2, 378], y=[1])from torch_geometric.utils import to_networkx
G = to_networkx(data=data)
print(G)DiGraph with 28 nodes and 378 edgesWe can plot the network:
%matplotlib inline
import networkx as nx
import matplotlib.pyplot as plt
# Visualization function for NX graph or PyTorch tensor
def visualize(h, color, epoch=None, loss=None, accuracy=None, node_size=300):
plt.figure(figsize=(7,7))
plt.xticks([])
plt.yticks([])
if torch.is_tensor(h):
h = h.detach().cpu().numpy()
plt.scatter(h[:, 0], h[:, 1], s=140, c=color, cmap="Set2")
if epoch is not None and loss is not None and accuracy['train'] is not None and accuracy['val'] is not None:
plt.xlabel((f'Epoch: {epoch}, Loss: {loss.item():.4f} \n'
f'Training Accuracy: {accuracy["train"]*100:.2f}% \n'
f' Validation Accuracy: {accuracy["val"]*100:.2f}%'),
fontsize=16)
else:
nx.draw_networkx(h, pos=nx.spring_layout(h, seed=4572321), with_labels=False,
node_color=color, cmap="Set2", node_size=40, alpha=0.6)
plt.show()visualize(G, color="cyan")c:\Users\LENOVO\miniconda3\envs\piero\lib\site-packages\networkx\drawing\nx_pylab.py:437: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
node_collection = ax.scatter(
Every node in this network is connected to all the other nodes. This will change with the model predictions.
Let’s see the 2-D dimentional reduction from the embeddings:
from sklearn.manifold import TSNE
tsne_components = TSNE(n_components=2, perplexity=5, init="pca").fit_transform(data.x)
plt.scatter(tsne_components[:,0], tsne_components[:,1],c="cyan", cmap="tab20b")C:\Users\LENOVO\AppData\Local\Temp\ipykernel_3324\233343671.py:5: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
plt.scatter(tsne_components[:,0], tsne_components[:,1],c="cyan", cmap="tab20b")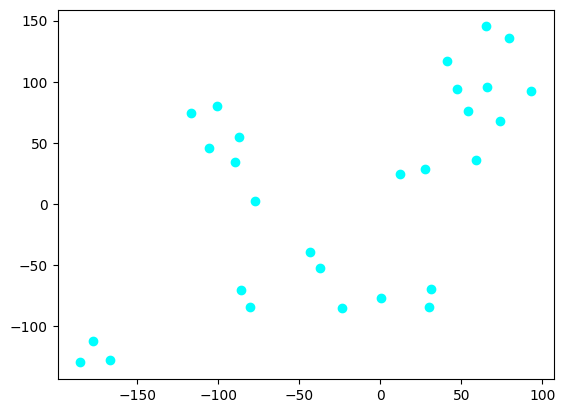
import torch.nn as nn
import torch.nn.functional as Ffrom torch_geometric.nn import SAGEConv
class GNNStack(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, dropout, num_layers:int, emb=False):
super(GNNStack, self).__init__()
self.dropout = dropout
self.num_layers = num_layers
self.emb = emb
self.convs = nn.ModuleList()
for layer in range(self.num_layers):
in_channels = input_dim if layer == 0 else hidden_dim
out_channels = hidden_dim
self.convs.append(SAGEConv(in_channels, out_channels, normalize=True))
self.post_mp = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.Dropout(self.dropout),
nn.Linear(hidden_dim, hidden_dim)
)
def forward(self, x, edge_index):
for i in range(self.num_layers):
x = self.convs[i](x, edge_index)
x = F.gelu(x)
x = F.dropout(x, p=self.dropout,training=self.training)
x = self.post_mp(x)
if self.emb == True:
return x
return F.log_softmax(x, dim=1)
def loss(self, pred, label):
return F.nll_loss(pred, label)class LinkPredictorHead(nn.Module):
def __init__(self, in_channels:int, hidden_channels:int, out_channels:int, n_layers:int,dropout_probabilty:float=0.3):
"""
Args:
in_channels (int): Number of input features.
hidden_channels (int): Number of hidden features.
out_channels (int): Number of output features.
n_layers (int): Number of MLP layers.
dropout (float): Dropout probability.
"""
super(LinkPredictorHead, self).__init__()
self.dropout_probabilty = dropout_probabilty # dropout probability
self.mlp_layers = nn.ModuleList() # ModuleList: is a list of modules
self.non_linearity = F.relu # non-linearity
for i in range(n_layers - 1):
if i == 0:
self.mlp_layers.append(nn.Linear(in_channels, hidden_channels)) # input layer (in_channels, hidden_channels)
else:
self.mlp_layers.append(nn.Linear(hidden_channels, hidden_channels)) # hidden layers (hidden_channels, hidden_channels)
self.mlp_layers.append(nn.Linear(hidden_channels, out_channels)) # output layer (hidden_channels, out_channels)
def reset_parameters(self):
for mlp_layer in self.mlp_layers:
mlp_layer.reset_parameters()
def forward(self, x_i, x_j):
x = x_i * x_j # element-wise multiplication
for mlp_layer in self.mlp_layers[:-1]: # iterate over all layers except the last one
x = mlp_layer(x) # apply linear transformation
x = self.non_linearity(x) # Apply non linear activation function
x = F.dropout(x, p=self.dropout_probabilty,training=self.training) # Apply dropout
x = self.mlp_layers[-1](x) # apply linear transformation to the last layer
x = torch.sigmoid(x) # apply sigmoid activation function to get the probability
return xLet’s load the model we trained before:
device = 'cuda' if torch.cuda.is_available() else 'cpu'
input_dim = data.x.shape[1]
hidden_dim = 1024
dropout = 0.3
num_layers= 3
model = GNNStack(input_dim, hidden_dim, hidden_dim, dropout,num_layers, emb=True).to(device) # the graph neural network that takes all the node embeddings as inputs to message pass and agregate
link_predictor = LinkPredictorHead(hidden_dim, hidden_dim, 1, num_layers , dropout).to(device)
best_graphsage_model_path = f"GraphSage_epoch_{404}.pt"
best_link_predictor_model_path = f"link_predictor_epoch_{404}.pt"
print(f"Loading best models: {best_graphsage_model_path } {best_link_predictor_model_path}")
checkpoint = torch.load(best_graphsage_model_path, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
model.eval()
checkpoint = torch.load(best_link_predictor_model_path, map_location=device)
link_predictor.load_state_dict(checkpoint['model_state_dict'])
link_predictor.eval()Loading best models: GraphSage_epoch_404.pt link_predictor_epoch_404.ptLinkPredictorHead(
(mlp_layers): ModuleList(
(0-1): 2 x Linear(in_features=1024, out_features=1024, bias=True)
(2): Linear(in_features=1024, out_features=1, bias=True)
)
)Now, let’s update our ProteinBERT embeddings:
x = torch.FloatTensor(data.x).to(device)
edge_index = data.edge_index.to(device)
embs = model(x, edge_index)
embs.shapetorch.Size([28, 1024])tsne_components = TSNE(n_components=2, perplexity=27, init="pca").fit_transform(embs.detach().cpu().numpy())
plt.scatter(tsne_components[:,0], tsne_components[:,1],c="cyan", cmap="tab20b")C:\Users\LENOVO\AppData\Local\Temp\ipykernel_3324\1092476614.py:3: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
plt.scatter(tsne_components[:,0], tsne_components[:,1],c="cyan", cmap="tab20b")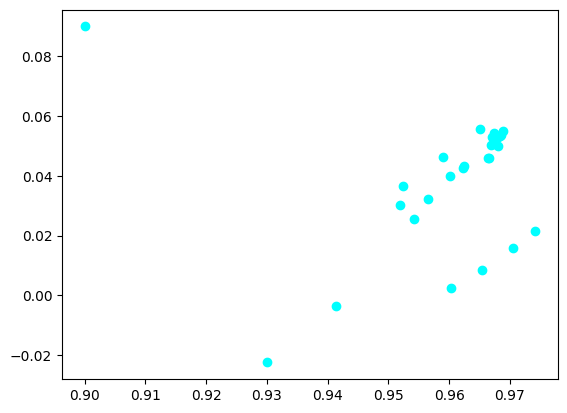
We can see a similar behaviour to the graph we plotted before.
Now, let’s pass those embedings to the LinkPredictorHead to get the probabilities of protein-protein interactions.
import itertools
def generate_pairs(num_embeddings):
pairs = itertools.combinations(range(num_embeddings), 2)
return list(pairs)
pairwise_combinations = generate_pairs(len(embs))results = []
with torch.no_grad(): # Ensure no gradients are computed
for i, j in pairwise_combinations:
vec1 = embs[i].unsqueeze(0) # Add batch dimension
vec2 = embs[j].unsqueeze(0) # Add batch dimension
prediction = link_predictor(vec1, vec2).item() # Convert to scalar
results.append((i, j, prediction))results[(0, 1, 0.6516209244728088),
(0, 2, 0.6353868246078491),
(0, 3, 0.1549677550792694),
(0, 4, 0.00240265647880733),
(0, 5, 0.6596815586090088),
(0, 6, 0.6366676688194275),
(0, 7, 0.6536526679992676),
(0, 8, 0.6611047387123108),
(0, 9, 0.6263799667358398),
(0, 10, 0.5428963303565979),
(0, 11, 0.5935388207435608),
(0, 12, 0.6135593056678772),
(0, 13, 0.6762287616729736),
(0, 14, 0.6489772796630859),
(0, 15, 0.6287089586257935),
(0, 16, 0.6755351424217224),
(0, 17, 0.6885703802108765),
(0, 18, 0.6545939445495605),
(0, 19, 0.6656283736228943),
(0, 20, 0.6443829536437988),
(0, 21, 0.6490920186042786),
(0, 22, 0.6958609223365784),
(0, 23, 0.6536524295806885),
(0, 24, 0.6821668744087219),
(0, 25, 0.6490938067436218),
(0, 26, 0.6867173910140991),
(0, 27, 0.6356632113456726),
(1, 2, 0.6407619118690491),
(1, 3, 0.16379830241203308),
(1, 4, 0.0026919585652649403),
(1, 5, 0.663702130317688),
(1, 6, 0.6410140991210938),
(1, 7, 0.6575544476509094),
(1, 8, 0.6650683283805847),
(1, 9, 0.6302982568740845),
(1, 10, 0.5495249032974243),
(1, 11, 0.5960684418678284),
(1, 12, 0.6183051466941833),
(1, 13, 0.6807677149772644),
(1, 14, 0.6529000401496887),
(1, 15, 0.6348029375076294),
(1, 16, 0.6794295310974121),
(1, 17, 0.6925675272941589),
(1, 18, 0.6591278314590454),
(1, 19, 0.6698798537254333),
(1, 20, 0.6476978063583374),
(1, 21, 0.6544296145439148),
(1, 22, 0.6998830437660217),
(1, 23, 0.657951831817627),
(1, 24, 0.6857574582099915),
(1, 25, 0.6525057554244995),
(1, 26, 0.6906378269195557),
(1, 27, 0.6393598318099976),
(2, 3, 0.1643204391002655),
(2, 4, 0.002355146687477827),
(2, 5, 0.6558791399002075),
(2, 6, 0.6311058402061462),
(2, 7, 0.6712092161178589),
(2, 8, 0.6630185842514038),
(2, 9, 0.6322583556175232),
(2, 10, 0.5704501867294312),
(2, 11, 0.5828412771224976),
(2, 12, 0.6378066539764404),
(2, 13, 0.69139564037323),
(2, 14, 0.6474908590316772),
(2, 15, 0.6154056787490845),
(2, 16, 0.68714439868927),
(2, 17, 0.7023219466209412),
(2, 18, 0.6431967616081238),
(2, 19, 0.6586276292800903),
(2, 20, 0.650769054889679),
(2, 21, 0.6362648010253906),
(2, 22, 0.7066485285758972),
(2, 23, 0.6588587164878845),
(2, 24, 0.6905868053436279),
(2, 25, 0.6514662504196167),
(2, 26, 0.6880756616592407),
(2, 27, 0.6354951858520508),
(3, 4, 0.03235967084765434),
(3, 5, 0.1512165665626526),
(3, 6, 0.1380177140235901),
(3, 7, 0.20171405375003815),
(3, 8, 0.1526450365781784),
(3, 9, 0.13056907057762146),
(3, 10, 0.23209062218666077),
(3, 11, 0.7857808470726013),
(3, 12, 0.21389544010162354),
(3, 13, 0.20203478634357452),
(3, 14, 0.14245127141475677),
(3, 15, 0.16068245470523834),
(3, 16, 0.17039823532104492),
(3, 17, 0.20283134281635284),
(3, 18, 0.17598101496696472),
(3, 19, 0.17448773980140686),
(3, 20, 0.14938104152679443),
(3, 21, 0.17380648851394653),
(3, 22, 0.22450312972068787),
(3, 23, 0.14858992397785187),
(3, 24, 0.19588254392147064),
(3, 25, 0.1469128578901291),
(3, 26, 0.19678889214992523),
(3, 27, 0.12700866162776947),
(4, 5, 0.0031711102928966284),
(4, 6, 0.002816929016262293),
(4, 7, 0.028047362342476845),
(4, 8, 0.004311413504183292),
(4, 9, 0.006255981046706438),
(4, 10, 0.04060244560241699),
(4, 11, 0.7456787824630737),
(4, 12, 0.033730071038007736),
(4, 13, 0.021687116473913193),
(4, 14, 0.003255143528804183),
(4, 15, 0.002582560759037733),
(4, 16, 0.01153197605162859),
(4, 17, 0.01686677150428295),
(4, 18, 0.0031696499790996313),
(4, 19, 0.003379370318725705),
(4, 20, 0.008798902854323387),
(4, 21, 0.0027418360114097595),
(4, 22, 0.01799710839986801),
(4, 23, 0.005963128991425037),
(4, 24, 0.013169199228286743),
(4, 25, 0.004866440314799547),
(4, 26, 0.005824151914566755),
(4, 27, 0.0032935740891844034),
(5, 6, 0.6407255530357361),
(5, 7, 0.6145603656768799),
(5, 8, 0.6539314389228821),
(5, 9, 0.6078476905822754),
(5, 10, 0.48655009269714355),
(5, 11, 0.6330196261405945),
(5, 12, 0.5605289936065674),
(5, 13, 0.6491217613220215),
(5, 14, 0.6484204530715942),
(5, 15, 0.6462467908859253),
(5, 16, 0.6530637741088867),
(5, 17, 0.6639900803565979),
(5, 18, 0.6656372547149658),
(5, 19, 0.6717554330825806),
(5, 20, 0.6260453462600708),
(5, 21, 0.6658167839050293),
(5, 22, 0.6743161678314209),
(5, 23, 0.6420108675956726),
(5, 24, 0.663898229598999),
(5, 25, 0.6400290727615356),
(5, 26, 0.683623731136322),
(5, 27, 0.6318883895874023),
(6, 7, 0.6121296882629395),
(6, 8, 0.6378514766693115),
(6, 9, 0.5936034917831421),
(6, 10, 0.48594003915786743),
(6, 11, 0.6049470901489258),
(6, 12, 0.5616738796234131),
(6, 13, 0.6440476775169373),
(6, 14, 0.6289294958114624),
(6, 15, 0.6212337017059326),
(6, 16, 0.6450724005699158),
(6, 17, 0.6578848361968994),
(6, 18, 0.6423628926277161),
(6, 19, 0.650640070438385),
(6, 20, 0.6123230457305908),
(6, 21, 0.6414790153503418),
(6, 22, 0.668196439743042),
(6, 23, 0.6280677318572998),
(6, 24, 0.6558521389961243),
(6, 25, 0.6238582730293274),
(6, 26, 0.6675381660461426),
(6, 27, 0.6140040159225464),
(7, 8, 0.5666692852973938),
(7, 9, 0.473154753446579),
(7, 10, 0.31759050488471985),
(7, 11, 0.786492645740509),
(7, 12, 0.3461472690105438),
(7, 13, 0.45529621839523315),
(7, 14, 0.6007402539253235),
(7, 15, 0.6579587459564209),
(7, 16, 0.4867945909500122),
(7, 17, 0.48854517936706543),
(7, 18, 0.6632601618766785),
(7, 19, 0.6519687175750732),
(7, 20, 0.478398859500885),
(7, 21, 0.6722728610038757),
(7, 22, 0.5271363854408264),
(7, 23, 0.5207403302192688),
(7, 24, 0.521931529045105),
(7, 25, 0.5416330099105835),
(7, 26, 0.6081287264823914),
(7, 27, 0.5660364627838135),
(8, 9, 0.5807303786277771),
(8, 10, 0.43117350339889526),
(8, 11, 0.653941810131073),
(8, 12, 0.5005493760108948),
(8, 13, 0.6095291972160339),
(8, 14, 0.6396584510803223),
(8, 15, 0.6509921550750732),
(8, 16, 0.6240960955619812),
(8, 17, 0.6322875618934631),
(8, 18, 0.6669977307319641),
(8, 19, 0.6707509756088257),
(8, 20, 0.5967980623245239),
(8, 21, 0.6697534322738647),
(8, 22, 0.6486610770225525),
(8, 23, 0.6173009872436523),
(8, 24, 0.6384821534156799),
(8, 25, 0.6230064034461975),
(8, 26, 0.6710716485977173),
(8, 27, 0.6209467649459839),
(9, 10, 0.33942732214927673),
(9, 11, 0.6700907349586487),
(9, 12, 0.40345248579978943),
(9, 13, 0.5232086181640625),
(9, 14, 0.5914512276649475),
(9, 15, 0.6193699836730957),
(9, 16, 0.5470945239067078),
(9, 17, 0.5522660613059998),
(9, 18, 0.6310119032859802),
(9, 19, 0.6317589282989502),
(9, 20, 0.5196877121925354),
(9, 21, 0.6380939483642578),
(9, 22, 0.5786010026931763),
(9, 23, 0.5554651021957397),
(9, 24, 0.5697511434555054),
(9, 25, 0.5597211718559265),
(9, 26, 0.6233639717102051),
(9, 27, 0.5657612085342407),
(10, 11, 0.8320461511611938),
(10, 12, 0.2759856879711151),
(10, 13, 0.36178725957870483),
(10, 14, 0.4756852090358734),
(10, 15, 0.5591267347335815),
(10, 16, 0.3717026114463806),
(10, 17, 0.3837338387966156),
(10, 18, 0.5580776333808899),
(10, 19, 0.5381458401679993),
(10, 20, 0.35380661487579346),
(10, 21, 0.5728854537010193),
(10, 22, 0.41806942224502563),
(10, 23, 0.38928279280662537),
(10, 24, 0.40968748927116394),
(10, 25, 0.4041808843612671),
(10, 26, 0.4880358874797821),
(10, 27, 0.43004876375198364),
(11, 12, 0.8281411528587341),
(11, 13, 0.7587007284164429),
(11, 14, 0.6126635074615479),
(11, 15, 0.5350322723388672),
(11, 16, 0.7190828323364258),
(11, 17, 0.7444915175437927),
(11, 18, 0.5951054096221924),
(11, 19, 0.6181790232658386),
(11, 20, 0.6915994882583618),
(11, 21, 0.5739037394523621),
(11, 22, 0.6954312324523926),
(11, 23, 0.6608714461326599),
(11, 24, 0.6787600517272949),
(11, 25, 0.6585936546325684),
(11, 26, 0.6285814046859741),
(11, 27, 0.6335501074790955),
(12, 13, 0.3908439874649048),
(12, 14, 0.5473573207855225),
(12, 15, 0.6265749335289001),
(12, 16, 0.4187116324901581),
(12, 17, 0.42472636699676514),
(12, 18, 0.6254512071609497),
(12, 19, 0.6057702302932739),
(12, 20, 0.410260409116745),
(12, 21, 0.6382721662521362),
(12, 22, 0.4646744430065155),
(12, 23, 0.45221537351608276),
(12, 24, 0.45593759417533875),
(12, 25, 0.47443559765815735),
(12, 26, 0.5471859574317932),
(12, 27, 0.5039544701576233),
(13, 14, 0.6351994872093201),
(13, 15, 0.6790755987167358),
(13, 16, 0.5415701866149902),
(13, 17, 0.5441862344741821),
(13, 18, 0.6867060661315918),
(13, 19, 0.6789133548736572),
(13, 20, 0.5312950015068054),
(13, 21, 0.6924731135368347),
(13, 22, 0.5747604370117188),
(13, 23, 0.5711761116981506),
(13, 24, 0.5694891810417175),
(13, 25, 0.5893358588218689),
(13, 26, 0.6470932960510254),
(13, 27, 0.6072432398796082),
(14, 15, 0.6351761817932129),
(14, 16, 0.6383631825447083),
(14, 17, 0.6506357789039612),
(14, 18, 0.6555088758468628),
(14, 19, 0.6611577272415161),
(14, 20, 0.6099813580513),
(14, 21, 0.6557841897010803),
(14, 22, 0.6608516573905945),
(14, 23, 0.6267029047012329),
(14, 24, 0.6494652628898621),
(14, 25, 0.6262791156768799),
(14, 26, 0.6703994870185852),
(14, 27, 0.6172877550125122),
(15, 16, 0.6741568446159363),
(15, 17, 0.6897742748260498),
(15, 18, 0.6372163891792297),
(15, 19, 0.6502119302749634),
(15, 20, 0.6392190456390381),
(15, 21, 0.6295965313911438),
(15, 22, 0.6940183043479919),
(15, 23, 0.6454131007194519),
(15, 24, 0.6772948503494263),
(15, 25, 0.6392379403114319),
(15, 26, 0.6756613254547119),
(15, 27, 0.623073399066925),
(16, 17, 0.5736261010169983),
(16, 18, 0.683904230594635),
(16, 19, 0.6805753111839294),
(16, 20, 0.5568569898605347),
(16, 21, 0.6898322105407715),
(16, 22, 0.6020229458808899),
(16, 23, 0.593259871006012),
(16, 24, 0.5982497334480286),
(16, 25, 0.6057554483413696),
(16, 26, 0.6600492596626282),
(16, 27, 0.6153603196144104),
(17, 18, 0.6978296041488647),
(17, 19, 0.6904391646385193),
(17, 20, 0.5623536705970764),
(17, 21, 0.7035311460494995),
(17, 22, 0.6020848751068115),
(17, 23, 0.59806227684021),
(17, 24, 0.6001761555671692),
(17, 25, 0.6134010553359985),
(17, 26, 0.6648403406143188),
(17, 27, 0.625240683555603),
(18, 19, 0.6715191602706909),
(18, 20, 0.6481854915618896),
(18, 21, 0.6572598814964294),
(18, 22, 0.70438152551651),
(18, 23, 0.6600649356842041),
(18, 24, 0.688887894153595),
(18, 25, 0.6536574363708496),
(18, 26, 0.6930991411209106),
(18, 27, 0.6409668922424316),
(19, 20, 0.6499772667884827),
(19, 21, 0.6694555282592773),
(19, 22, 0.6986953616142273),
(19, 23, 0.6628071665763855),
(19, 24, 0.6879525184631348),
(19, 25, 0.6575807332992554),
(19, 26, 0.6970205307006836),
(19, 27, 0.6467885375022888),
(20, 21, 0.657131016254425),
(20, 22, 0.5877546072006226),
(20, 23, 0.571294903755188),
(20, 24, 0.5778743624687195),
(20, 25, 0.5762938261032104),
(20, 26, 0.6398497223854065),
(20, 27, 0.5857248902320862),
(21, 22, 0.7083775997161865),
(21, 23, 0.6642312407493591),
(21, 24, 0.6941034197807312),
(21, 25, 0.658011794090271),
(21, 26, 0.6938483715057373),
(21, 27, 0.6433342695236206),
(22, 23, 0.6195434927940369),
(22, 24, 0.6229152679443359),
(22, 25, 0.6323350667953491),
(22, 26, 0.6771524548530579),
(22, 27, 0.6395193338394165),
(23, 24, 0.6132277846336365),
(23, 25, 0.600766658782959),
(23, 26, 0.6547662019729614),
(23, 27, 0.603947103023529),
(24, 25, 0.6209597587585449),
(24, 26, 0.6712677478790283),
(24, 27, 0.6275331974029541),
(25, 26, 0.6600415706634521),
(25, 27, 0.6034719944000244),
(26, 27, 0.6551728844642639)]Let’s put those probabilities to a sorted dataframe:
results_df = pd.DataFrame(results, columns=["Protein1", "Protein2", "Prediction"])
# Sort the DataFrame by prediction score in descending order
results_df = results_df.sort_values(by="Prediction", ascending=False)
results_df| Protein1 | Protein2 | Prediction | |
|---|---|---|---|
| 225 | 10 | 11 | 0.832046 |
| 242 | 11 | 12 | 0.828141 |
| 171 | 7 | 11 | 0.786493 |
| 85 | 3 | 11 | 0.785781 |
| 243 | 11 | 13 | 0.758701 |
| ... | ... | ... | ... |
| 118 | 4 | 21 | 0.002742 |
| 29 | 1 | 4 | 0.002692 |
| 112 | 4 | 15 | 0.002583 |
| 3 | 0 | 4 | 0.002403 |
| 54 | 2 | 4 | 0.002355 |
378 rows × 3 columns
Here, we can filter out probabilities less than 50%:
mask = results_df["Prediction"] > 0.5
filtered_results_df = results_df[mask]
filtered_results_df| Protein1 | Protein2 | Prediction | |
|---|---|---|---|
| 225 | 10 | 11 | 0.832046 |
| 242 | 11 | 12 | 0.828141 |
| 171 | 7 | 11 | 0.786493 |
| 85 | 3 | 11 | 0.785781 |
| 243 | 11 | 13 | 0.758701 |
| ... | ... | ... | ... |
| 184 | 7 | 24 | 0.521932 |
| 183 | 7 | 23 | 0.520740 |
| 217 | 9 | 20 | 0.519688 |
| 272 | 12 | 27 | 0.503954 |
| 191 | 8 | 12 | 0.500549 |
295 rows × 3 columns
And, get back the protein ID’s:
filtered_results_df["Protein1"] = lbl_protein.inverse_transform(filtered_results_df["Protein1"])
filtered_results_df["Protein2"] = lbl_protein.inverse_transform(filtered_results_df["Protein2"])
filtered_results_dfC:\Users\LENOVO\AppData\Local\Temp\ipykernel_3324\338268944.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
filtered_results_df["Protein1"] = lbl_protein.inverse_transform(filtered_results_df["Protein1"])
C:\Users\LENOVO\AppData\Local\Temp\ipykernel_3324\338268944.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
filtered_results_df["Protein2"] = lbl_protein.inverse_transform(filtered_results_df["Protein2"])| Protein1 | Protein2 | Prediction | |
|---|---|---|---|
| 225 | XP_027084938.1 | XP_027084939.1 | 0.832046 |
| 242 | XP_027084939.1 | XP_027085429.1 | 0.828141 |
| 171 | XP_027084168.1 | XP_027084939.1 | 0.786493 |
| 85 | XP_027066556.1 | XP_027084939.1 | 0.785781 |
| 243 | XP_027084939.1 | XP_027089120.1 | 0.758701 |
| ... | ... | ... | ... |
| 184 | XP_027084168.1 | XP_027113320.1 | 0.521932 |
| 183 | XP_027084168.1 | XP_027110886.1 | 0.520740 |
| 217 | XP_027084891.1 | XP_027109657.1 | 0.519688 |
| 272 | XP_027085429.1 | XP_027125186.1 | 0.503954 |
| 191 | XP_027084272.1 | XP_027085429.1 | 0.500549 |
295 rows × 3 columns
To check, let’s left-join the first dsf to the filtered to see that the protein ID’s are correct:
filtered_results_df = pd.merge(
filtered_results_df,
df,
how='left',
left_on=['Protein1', 'Protein2'],
right_on=['Protein1', 'Protein2']
)
filtered_results_df = filtered_results_df.drop(columns=['node1_string_id', 'node2_string_id'])
filtered_results_df = filtered_results_df.sort_values(by="Prediction", ascending=False)
# Display the filtered results DataFrame
print(filtered_results_df) Protein1 Protein2 Prediction
0 XP_027084938.1 XP_027084939.1 0.832046
1 XP_027084939.1 XP_027085429.1 0.828141
2 XP_027084168.1 XP_027084939.1 0.786493
3 XP_027066556.1 XP_027084939.1 0.785781
4 XP_027084939.1 XP_027089120.1 0.758701
.. ... ... ...
290 XP_027084168.1 XP_027113320.1 0.521932
291 XP_027084168.1 XP_027110886.1 0.520740
292 XP_027084891.1 XP_027109657.1 0.519688
293 XP_027085429.1 XP_027125186.1 0.503954
294 XP_027084272.1 XP_027085429.1 0.500549
[295 rows x 3 columns]And, we can plot the graph with the edges coloured by the predicted probaility of interaction:
import networkx as nx
G = nx.Graph()
# Add edges to the graph
for index, row in filtered_results_df.iterrows():
G.add_edge(row['Protein1'], row['Protein2'], weight=round(row['Prediction'],3))
# Print some info about the graph
print(G)Graph with 28 nodes and 295 edgesimport pandas as pd
import networkx as nx
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import matplotlib.cm as cm
import matplotlib as mpl
from mpl_toolkits.axes_grid1 import make_axes_locatable
# Define the plot size and create a subplot
fig, ax = plt.subplots(figsize=(14, 14))
# Get edge weights and normalize them
weights = nx.get_edge_attributes(G, 'weight').values()
# Define the layout for the nodes
pos = nx.spring_layout(G, seed=120, weight='weight') # for consistent layout
# Draw the nodes
nx.draw_networkx_nodes(G, pos, node_size=700, ax=ax)
norm = mcolors.Normalize(vmin=min(weights), vmax=max(weights))
cmap = cm.jet
# Draw the edges with colors based on the weights
edges = G.edges(data=True)
edge_colors = [cmap(norm(weight['weight'])) for _, _, weight in edges]
edge_alphas = [norm(weight['weight']) for _, _, weight in edges]
nx.draw_networkx_edges(G, pos, edge_color=edge_colors, width=1.0, alpha=edge_alphas, ax=ax)
# Draw the labels
nx.draw_networkx_labels(G, pos, font_size=9, font_family="sans-serif", ax=ax)
# Add edge weights as labels (optional)
edge_labels = nx.get_edge_attributes(G, 'weight')
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_size=5, ax=ax)
# Create a colorbar as a legend
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.1)
sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)
sm.set_array([])
cbar = plt.colorbar(sm, cax=cax)
cbar.set_label('Prediction Probability')
# Show the plot
plt.title("Protein-Protein Interaction Network")
plt.axis('off') # Turn off the axis
plt.savefig("protein_interaction_network.svg", format='svg')
plt.show()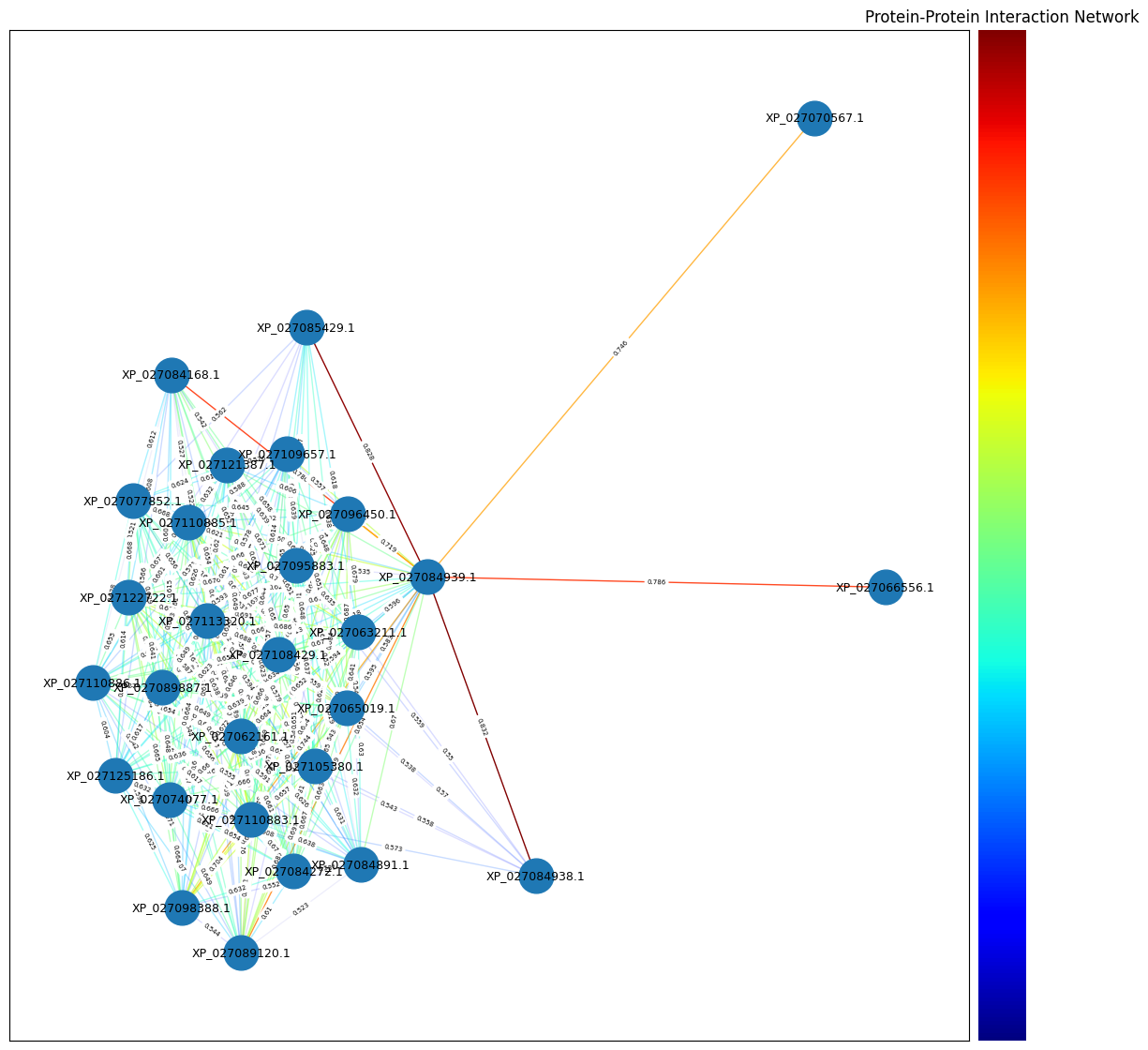
We can see that have a “medium” probaility of interaction based on their protein sequences. Doing a small search, most of the proteins in the messy part of the network are small heatshock protein sequences. It would be interesting to investigate the strong relations and if this have a biological meeaning like: these proteins are in the same compartment?